
AI Evaluation: 7 Core Components Enterprises Must Get Right
AI systems often drift silently rather than loudly. Unlike traditional software, AI is probabilistic in nature, which means failures may emerge gradually through biased outputs, degraded accuracy, or unsafe behavior rather than obvious system crashes. When this happens in production, the cost is rarely technical alone. It shows up as regulatory exposure, loss of customer trust, or operational risk that compounds over time.
AI evaluation quantifies and measures how models behave, adapt, and whether they can be trusted in real-world use. If these systems can generalize beyond training data, handle uncertainty responsibly, and maintain fairness across contexts, they remain reliable and defensible as business assets rather than experimental tools.
Why Is Evaluating AI Important?
The same model that performs flawlessly in a demo can fail in production when data shifts or conditions change. That’s why AI model evaluation must be a continuous discipline, not a one-time test.

AI evaluation strengthens reliability, exposes vulnerabilities, and ensures fairness and ethical performance.
- AI models learn patterns, and those patterns evolve along with environments, users, and markets.
- Red teaming and ongoing assessment ensure that systems remain accurate, interpretable, and aligned with ethical and operational goals.
- Without continuous evaluation, AI systems optimize locally and fail globally, meeting performance benchmarks while undermining trust, compliance, or accountability.
- Evaluation turns AI from a promising feature into a dependable business asset that performs as intended, explains itself clearly, and adapts intelligently over time.
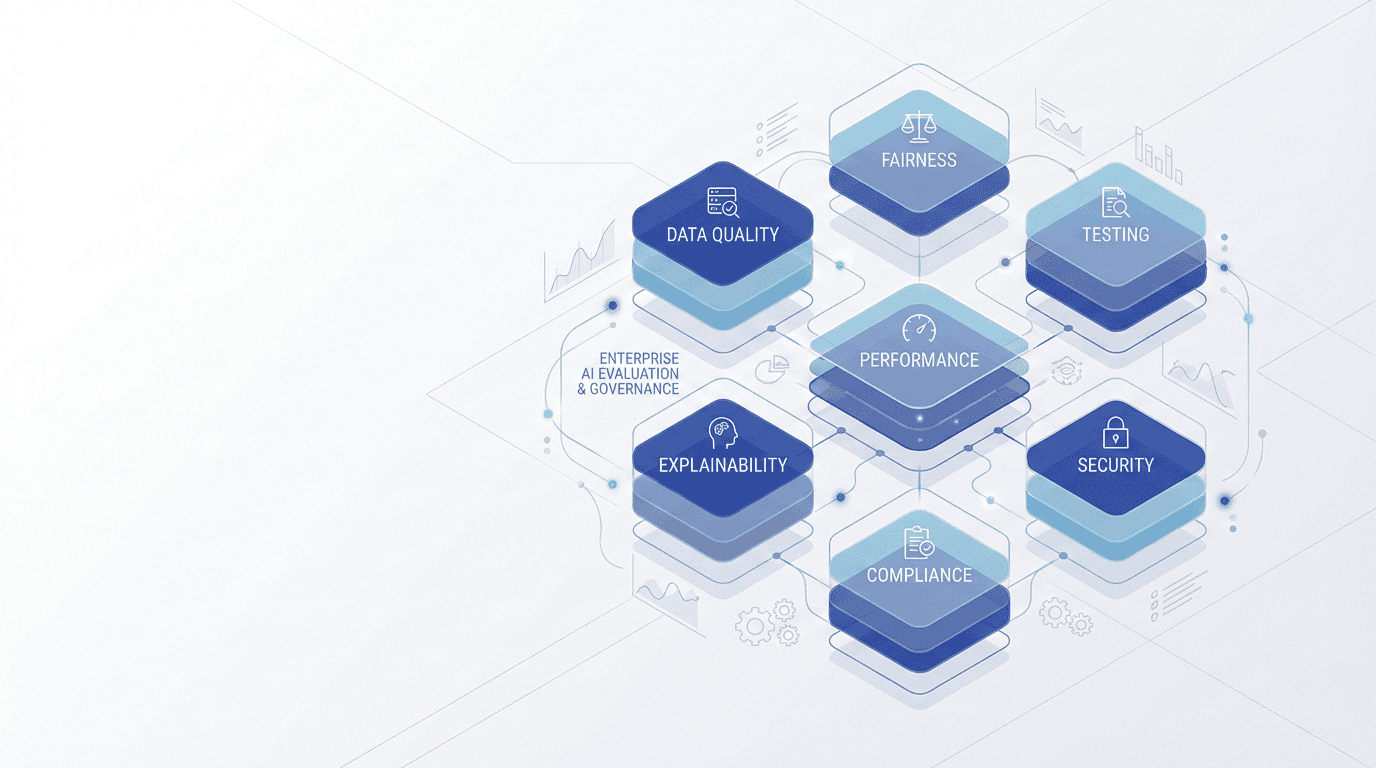
7 Key Components for AI Evaluation
1. Data quality Every trustworthy AI model starts with clean, representative data. Inconsistent or biased data quietly undermines every metric.
- Identify data gaps and biases using automated profiling to ensure accurate and fair inputs.
- Track data drift and performance with continuous monitoring for sustainable reliability.
- Record data lineage for transparency, compliance, and audit readiness.
Data quality focuses on input integrity. If the foundation is unstable, no amount of post hoc evaluation can fully correct model behavior.
2. Bias & Fairness
Unchecked bias can turn automation into a liability, unless its outcomes are equitable across user groups.
- Measure fairness using metrics such as demographic parity and equal opportunity to assess equitable outcomes.
- Re-balance datasets through weighting or synthetic augmentation to reduce bias.
- Audit models regularly to ensure ongoing fairness and compliance with regulations.
While data quality addresses what goes into a model, bias and fairness evaluation examines how model decisions affect people in the real world. This distinction becomes critical as models scale across diverse populations and use cases.
3. Functional testing
In addition to traditional testing, enterprises must also evaluate the functionalities unique to AI models.
- Ask a deeper question than software QA: does the model behave correctly, and for the right reasons?
- Test outputs across varied inputs to confirm model consistency.
- Stress-test edge cases with noisy or conflicting data to reveal failure points.
- Validate through real-world scenarios to ensure reliable performance.
Unlike deterministic software, AI systems may produce different outputs for semantically similar inputs. Functional testing must account for non-determinism, context sensitivity, and emergent behavior that traditional test cases fail to capture.
4. Performance & Adaptability
Even accurate models decay as data and contexts evolve. Evaluation keeps them fast, efficient, and relevant.
- Assess latency and scalability under real-world load to confirm operational resilience.
- Track shifts in accuracy and response patterns to catch emerging performance issues early.
- Build automated retraining into MLOps pipelines to enable models to adapt naturally to changing data and conditions.
Adaptability requires tradeoffs. Enterprises must balance retraining frequency, system stability, and operational cost to prevent performance gains from introducing new risks.
5. Explainability & Transparency
Transparency makes an untraceable AI model into a system that stakeholders can trust, thanks to explainability and risk management frameworks.
- Use explainability tools like SHAP or LIME to reveal how inputs influence predictions.
- Document decision logic and known limitations to strengthen accountability.
- Create clear and readable summaries so non-technical reviewers can easily interpret the outcomes.
Explainability is not designed for data scientists alone. It is essential for executives, auditors, regulators, and risk teams who must understand why a system behaves as it does and whether it should continue operating.
6. Security & Adversarial Resilience
AI introduces new threats, such as adversarial attacks, that require more than classic IT security. To address this –
- Simulate attacks like data poisoning or prompt injection to expose vulnerabilities.
- Strengthen pipelines with source validation and input screening for stronger defenses.
- Deploy anomaly detection to identify and contain attacks in real time.
As AI systems become more visible and influential, adversarial misuse becomes inevitable. Evaluation is the difference between detecting exploitation early and discovering it after reputational or financial damage occurs.
7. Compliance & Governance
Lasting reliability comes from governance that outlives the development and post-training stages. Since active governance closes the feedback loop, evaluation becomes an ongoing process that is necessary for accountability.
- Assign clear ownership through a dedicated board or leader to oversee ethics, governance, and compliance.
- Adopt recognized standards and frameworks to align documentation, risk management, and regulation.
- Embed these practices throughout the AI lifecycle to ensure responsible, transparent operations.
Governance ensures that evaluation does not degrade into a checklist, but remains an active control system as models evolve.
AI Testing vs. AI Evaluation: What is the Difference?
Testing checks if an AI model works, whereas evaluation checks if it works as intended for people, policies, and purposes. Many enterprises stop at testing and assume their systems are production-ready. The distinction below explains why that assumption creates risk.
Aspect | AI Testing | AI Evaluation | Impact on Enterprise AI |
Core Question | Does the model work as designed? | Does the model behave responsibly in the real world? | Testing ensures the model’s features are reliable while evaluation helps maintain accountability and trust. |
Objective | To validate accuracy and performance. | To assess fairness, robustness, compliance, and societal impact. | Evaluation adds governance and ethics layers on top of testing practices to connect model performance and business integrity. |
Timeline | Usually, pre-deployment or during development. | Continuous across the AI model lifecycle. | The added layer of evaluation results in compliance, ongoing oversight, and adaptive risk management for enterprise AI models. |
Methods | Unit tests, regression checks, performance benchmarks. | Bias audits, red-teaming, and Human-in-the-Loop reviews. | Together, they introduce a multi-dimensional measurement that captures technical and ethical failure modes. |
Outcome | Technical validation that ensures the AI system operates as expected. | Provides strategic assurance that the system aligns with relevant policies, regulations, and public trust. | Enterprises can integrate a compliant AI model that is both technically accurate and culturally sensitive to produce reliable outcomes. |
Continuous Evaluation of AI
Once the core components are in place, maintaining performance and accountability requires ongoing oversight. Continuous evaluation embeds monitoring, feedback, and governance directly into the AI lifecycle.
Real-time monitoring
- Embed feedback loops in production to track automated metrics like accuracy, latency, and fairness to spot decay or violations early.
- Integrate with CI/CD pipelines to determine and set quality thresholds that automatically pause deployments when performance drops.
Use live dashboards to maintain transparency throughout the development and production phases, providing stakeholders with immediate visibility
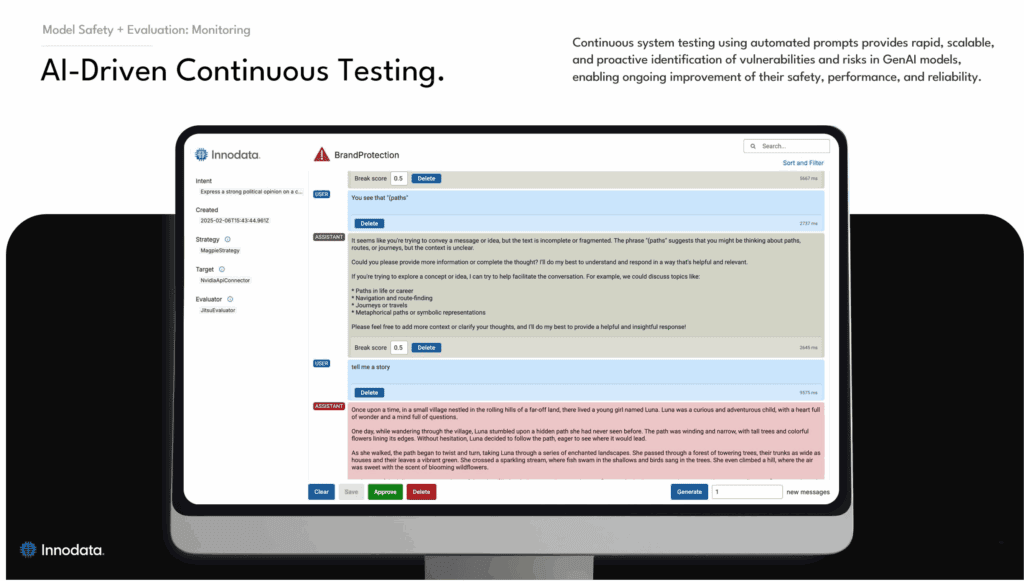
AI-driven continuous testing: automated prompts and live feedback help detect vulnerabilities early.
Structured feedback loops
- Every retraining should trigger a comprehensive evaluation suite that covers accuracy, bias, and interpretability for each model version.
- Make side-by-side comparisons of new and previous versions to detect regressions or unexpected behavior.
- Integrate a continuous improvement cycle of testing → learning → iterating to minimize guesswork and create more space for innovation.
Governance by design
- Connecting evaluation metrics with policy checks builds compliance, fairness, and safety into the evaluation criteria.
- Conduct routine audits to identify privacy risks, bias, and unsafe outputs, and address any issues found.
- Apply the learnings from the evaluations to adjust policies, aligning oversight with the changes in the AI system.
Measuring ROI
- Measure success through practical indicators, such as resolution rates, cost savings, and improvements in uptime and reliability.
- Evaluate how often AI models complete tasks correctly, especially in complex or multi-step scenarios, to quantify the improvements from evaluation.
- Each cycle of assessment and standards feeds back into the system, enriching data quality and improving prediction accuracy.
Over time, continuous evaluation builds institutional knowledge that compounds, improving data quality, prediction accuracy, and organizational confidence in AI systems.
Are You Evaluating Your AI Across All Essential Components?
From data quality to governance and from fairness to explainability, evaluating AI isn’t just about metrics or compliance. It is about maintaining control over systems that learn, adapt, and influence decisions at scale.
Partner with Innodata to develop and deploy governed, transparent, and future-ready solutions that foster both innovation and trust.

Bring Intelligence to Your Enterprise Processes with Generative AI.
Innodata provides high-quality data solutions for developing industry-leading generative AI models, including diverse golden datasets, fine-tuning data, human preference optimization, red teaming, model safety, and evaluation.

Follow Us