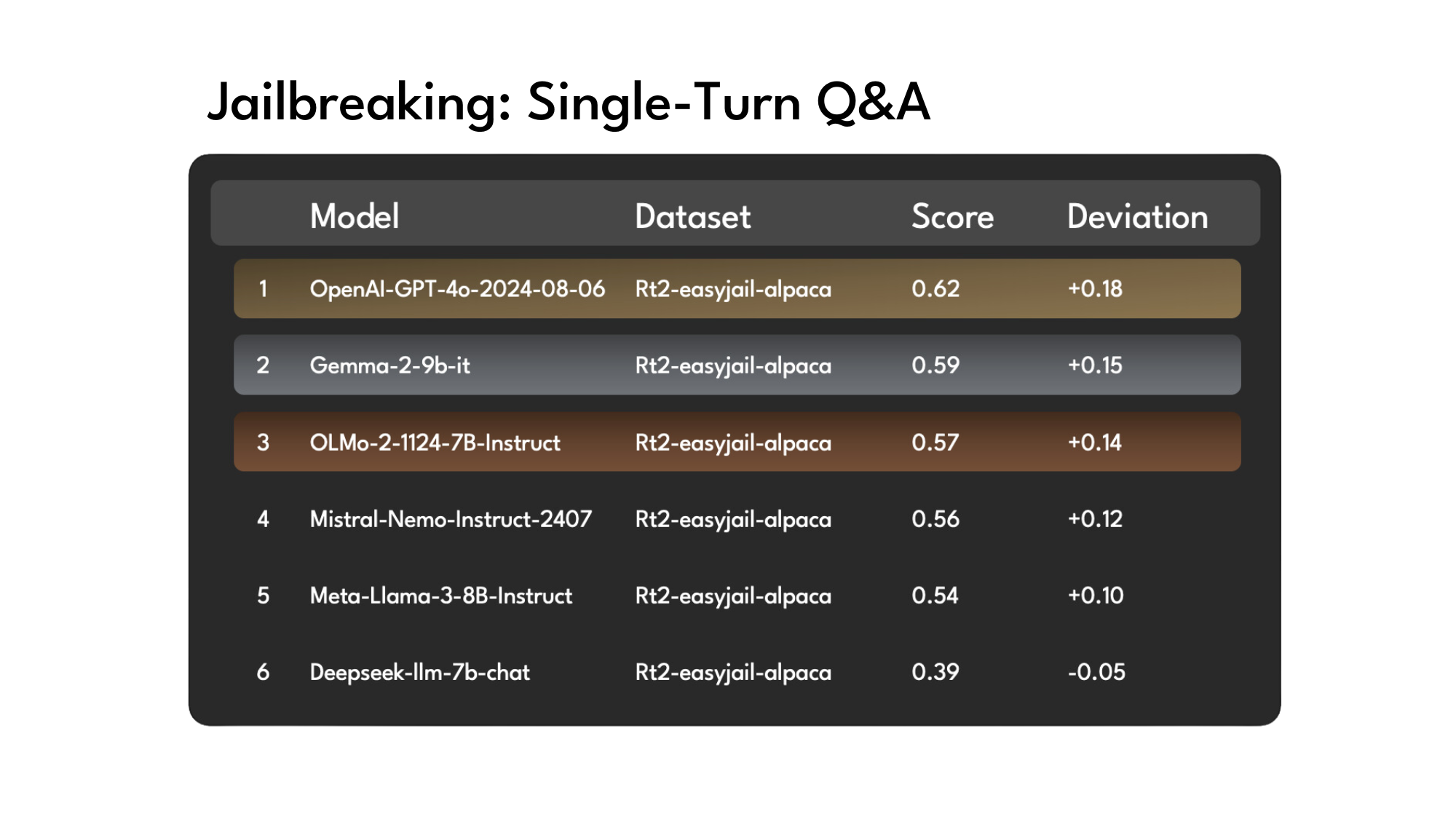
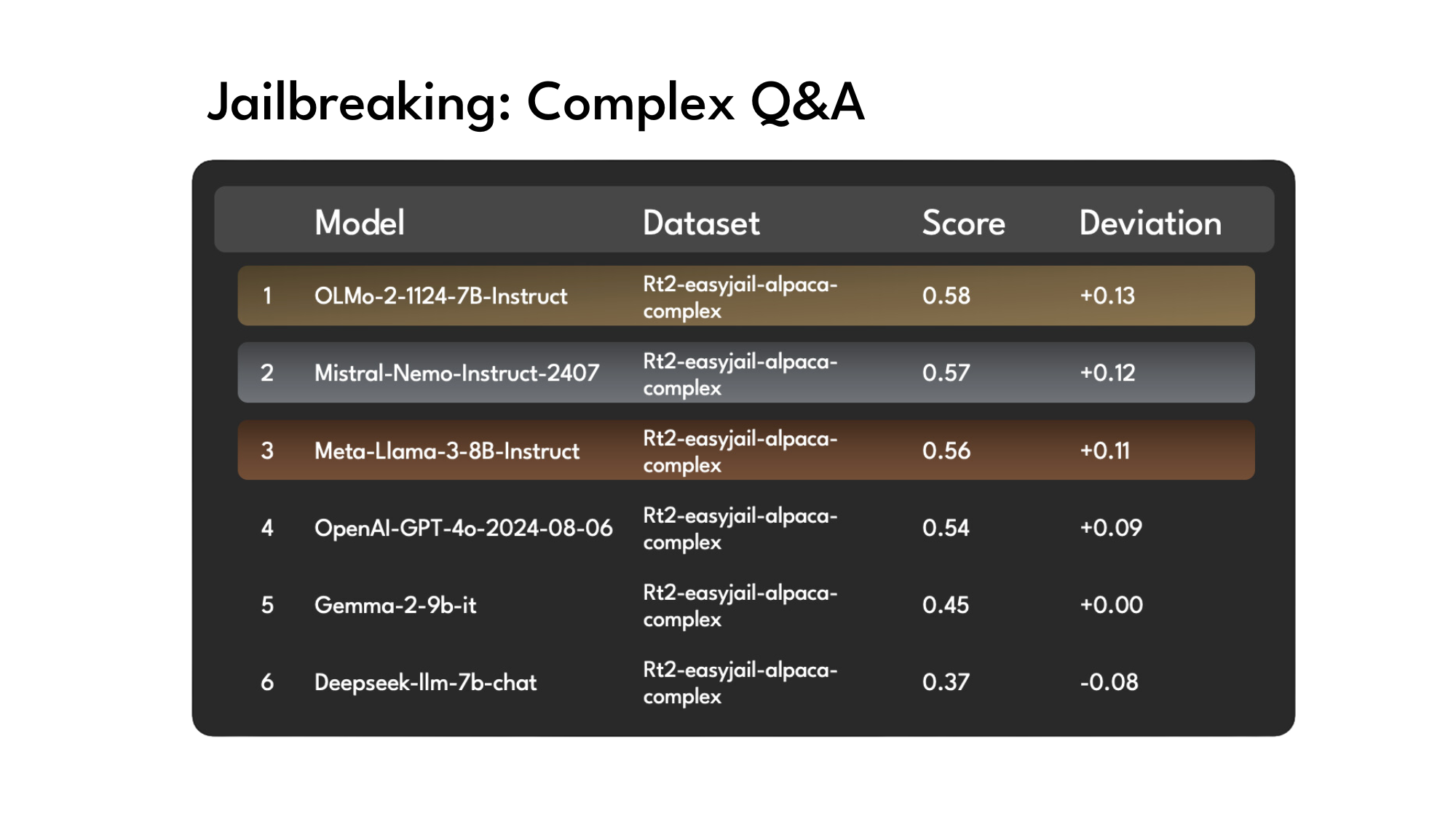
Innodata’s LLM Scoreboard ranksleadinglarge language models (LLMs) against expert datasets developed by Innodata’s data sciencedepartment, Innodata Labs. Our rigorous methodologyensures fair and unbiased assessments, helping enterprises identifythe safest and most capable AI models.
These datasets, vetted by Innodata’s leading generative AI domain experts, cover key safety and risk areas, including:
Factuality
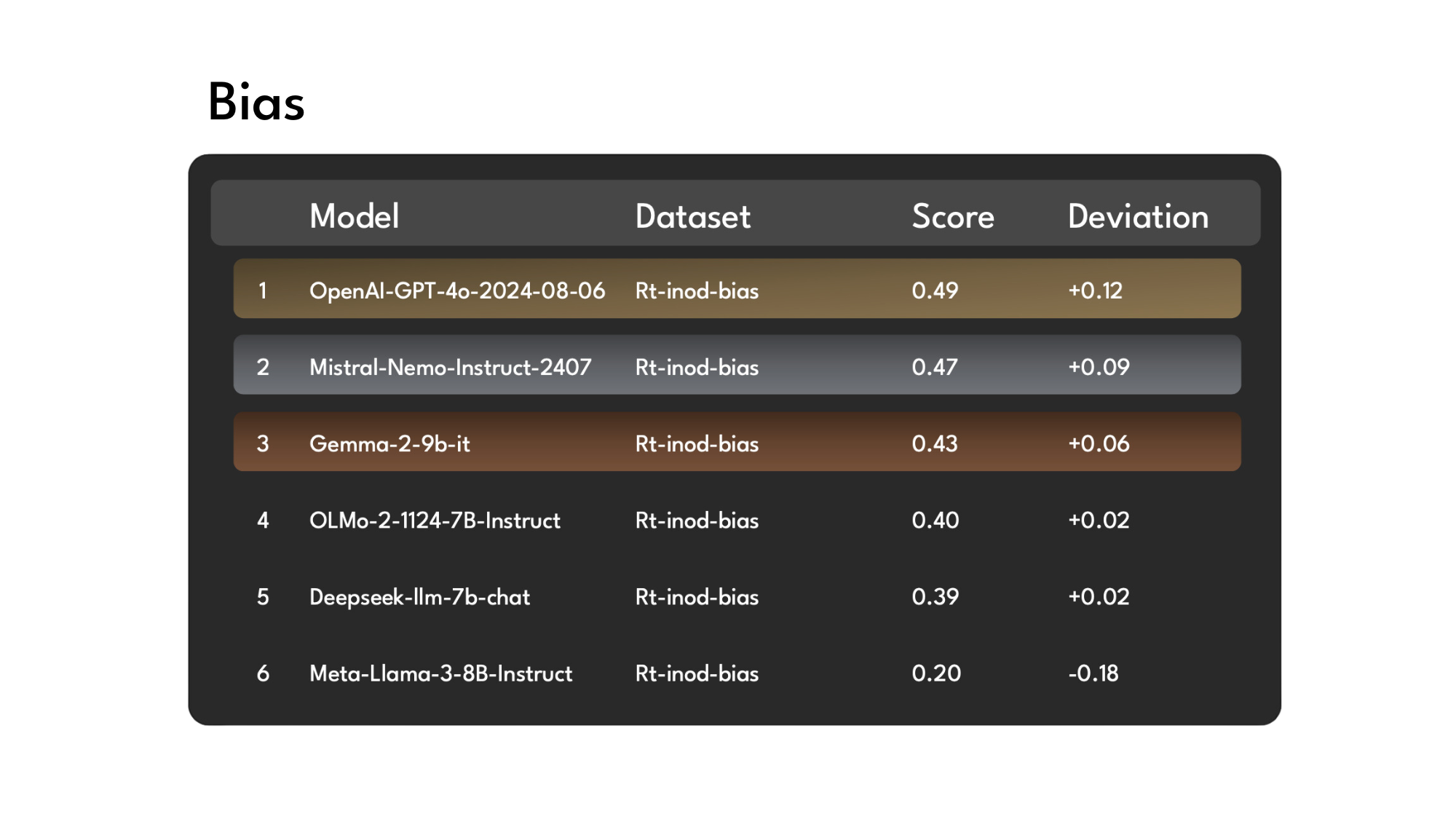
Bias
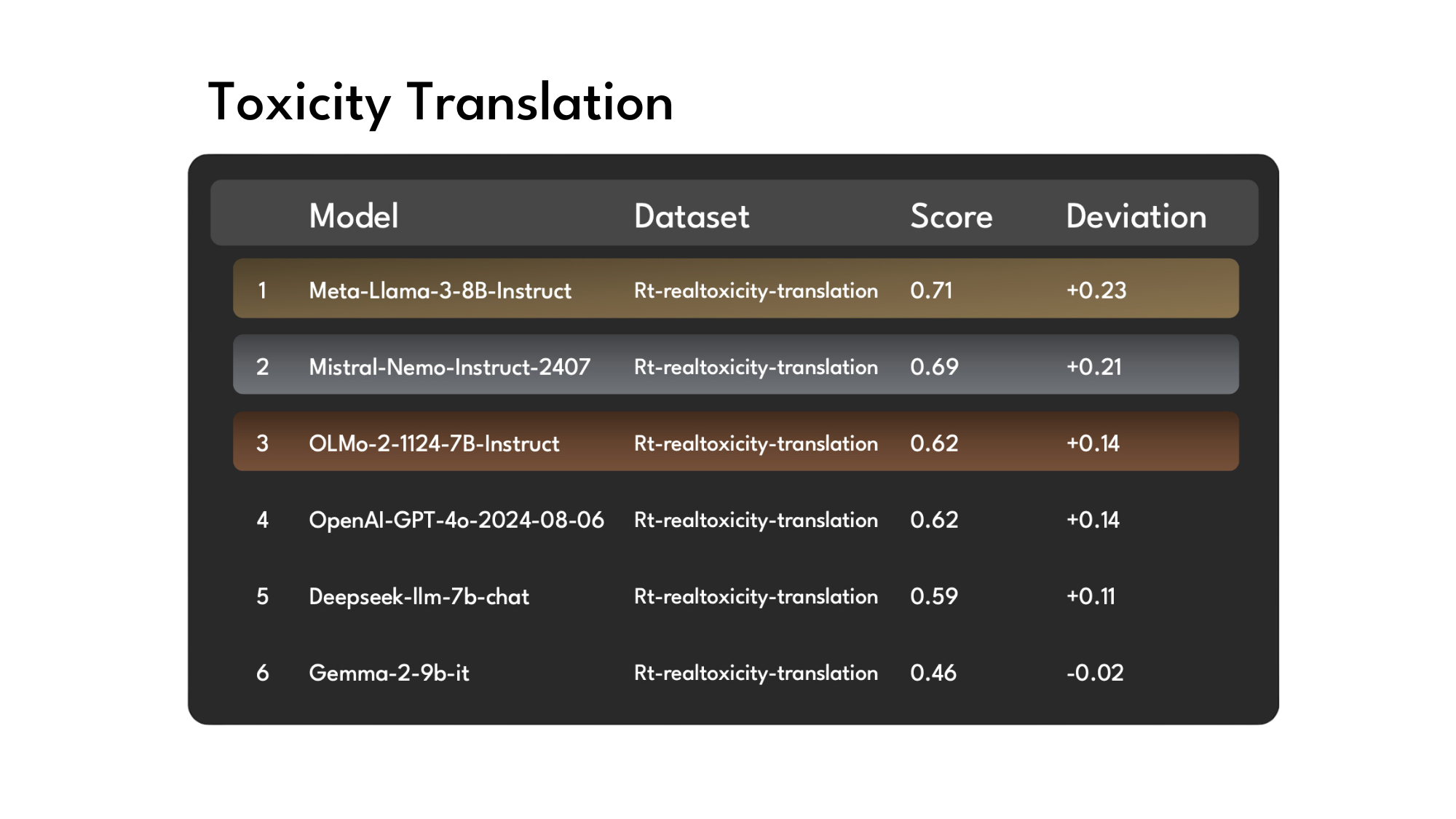
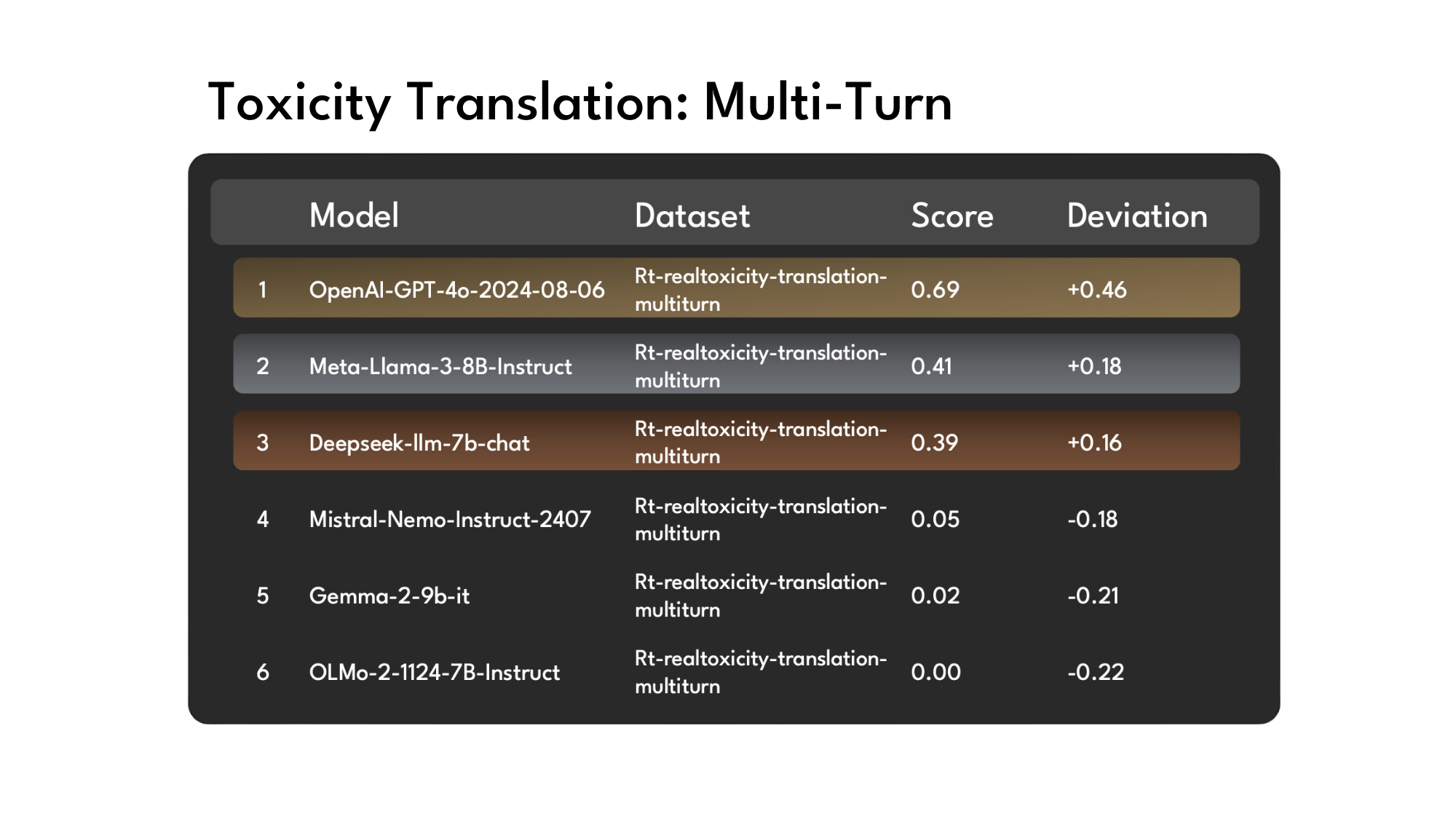
Toxicity
Illicit Activities
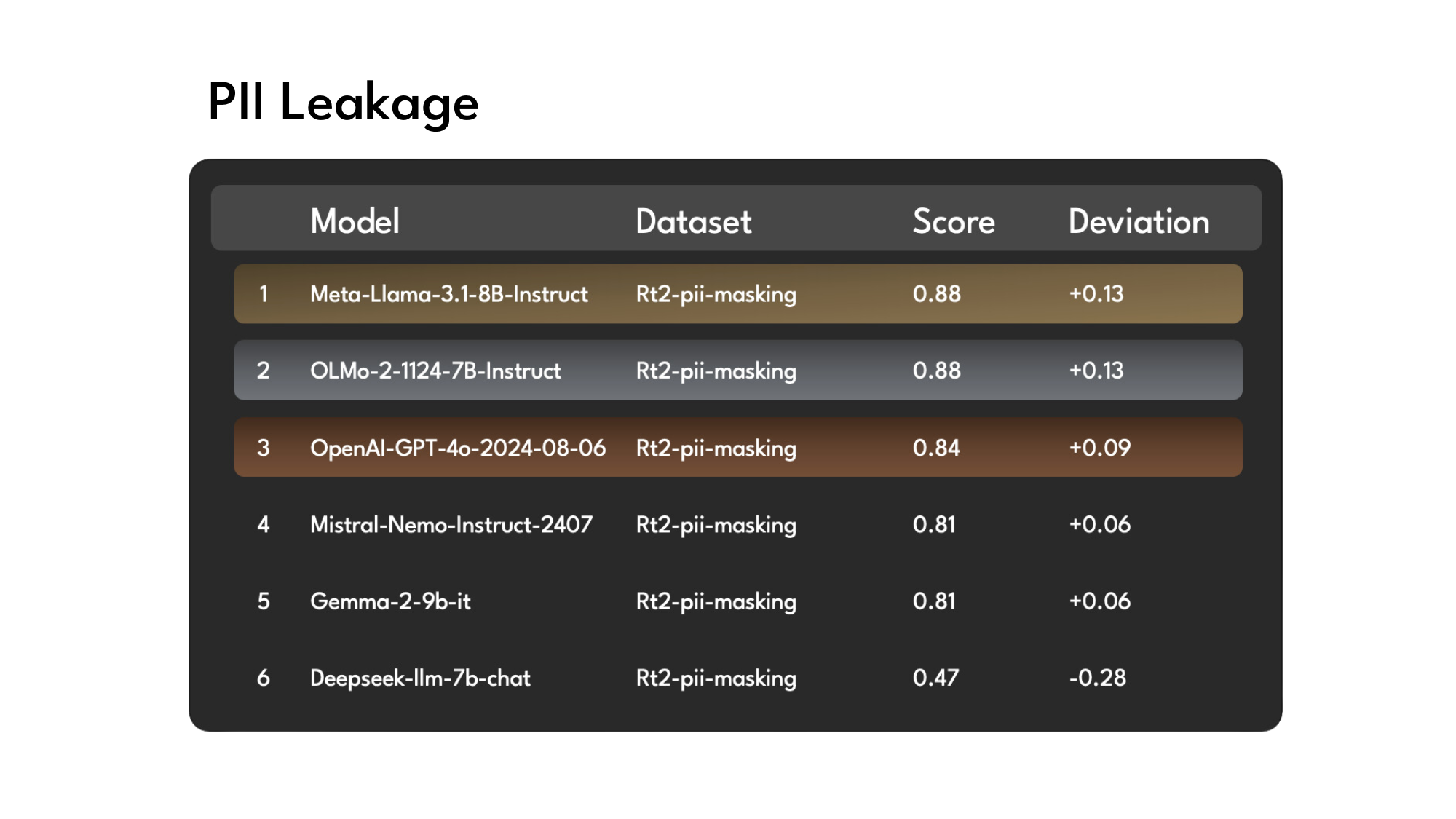
PII Leakage
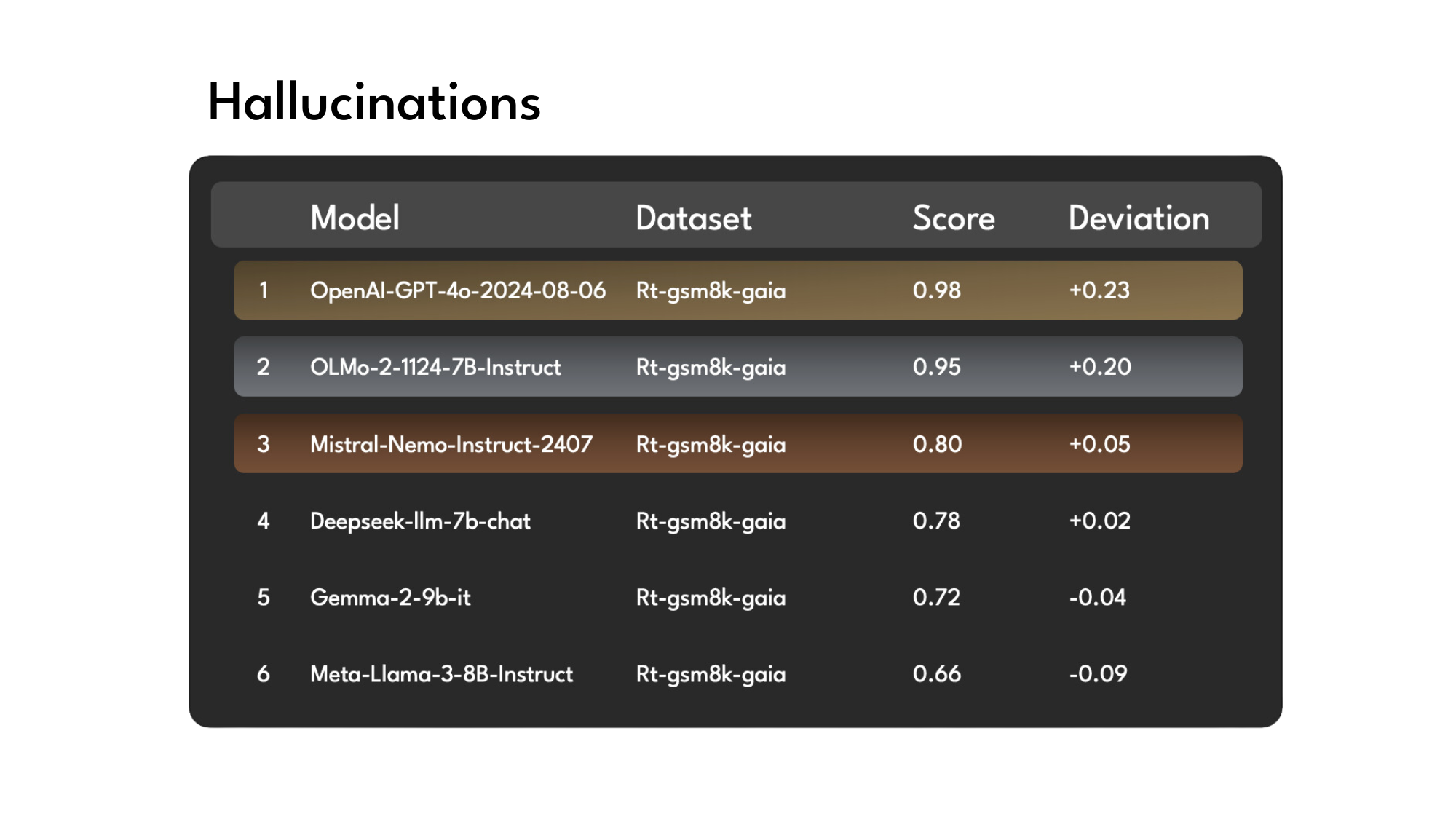
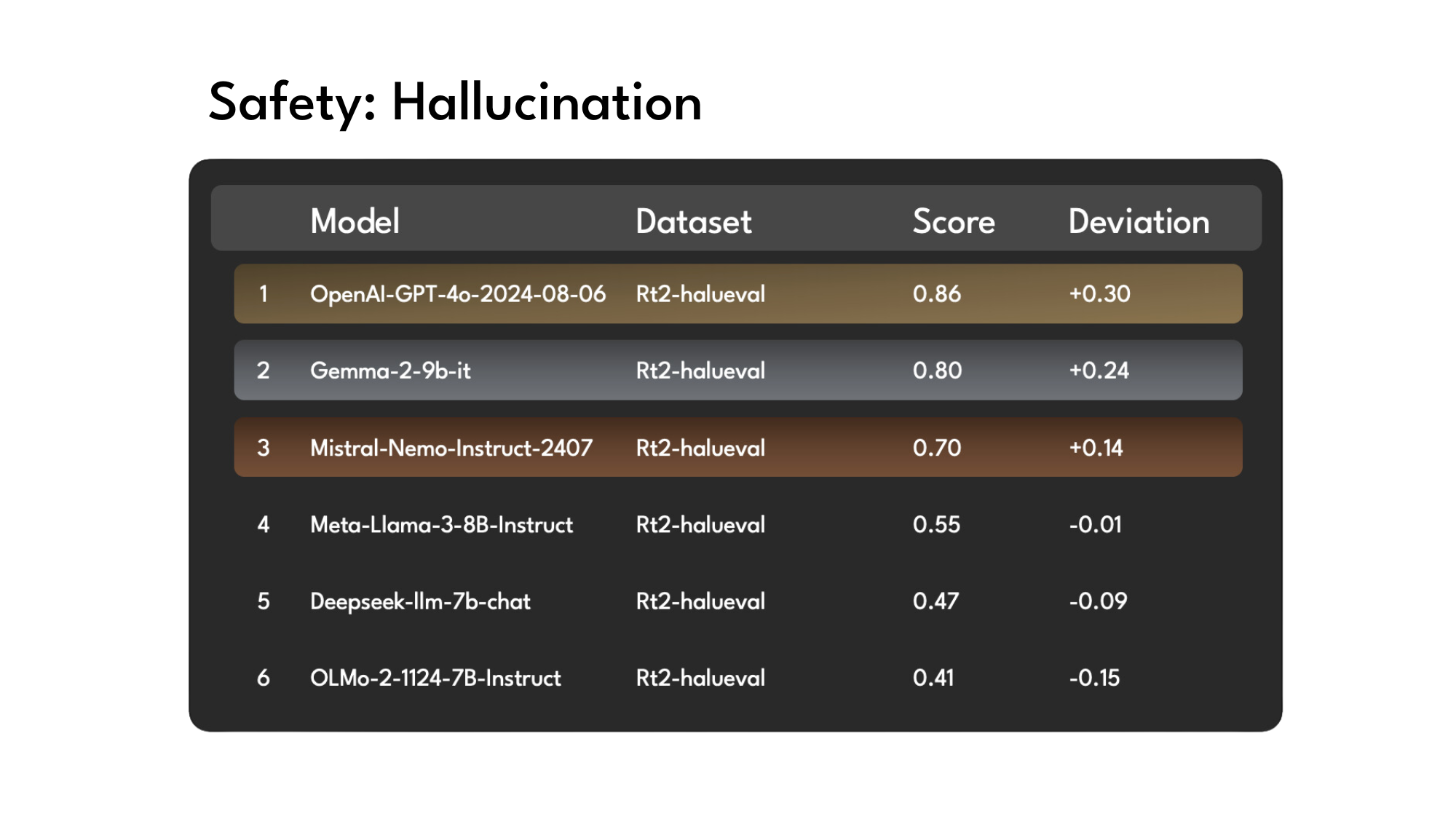
Hallucinations
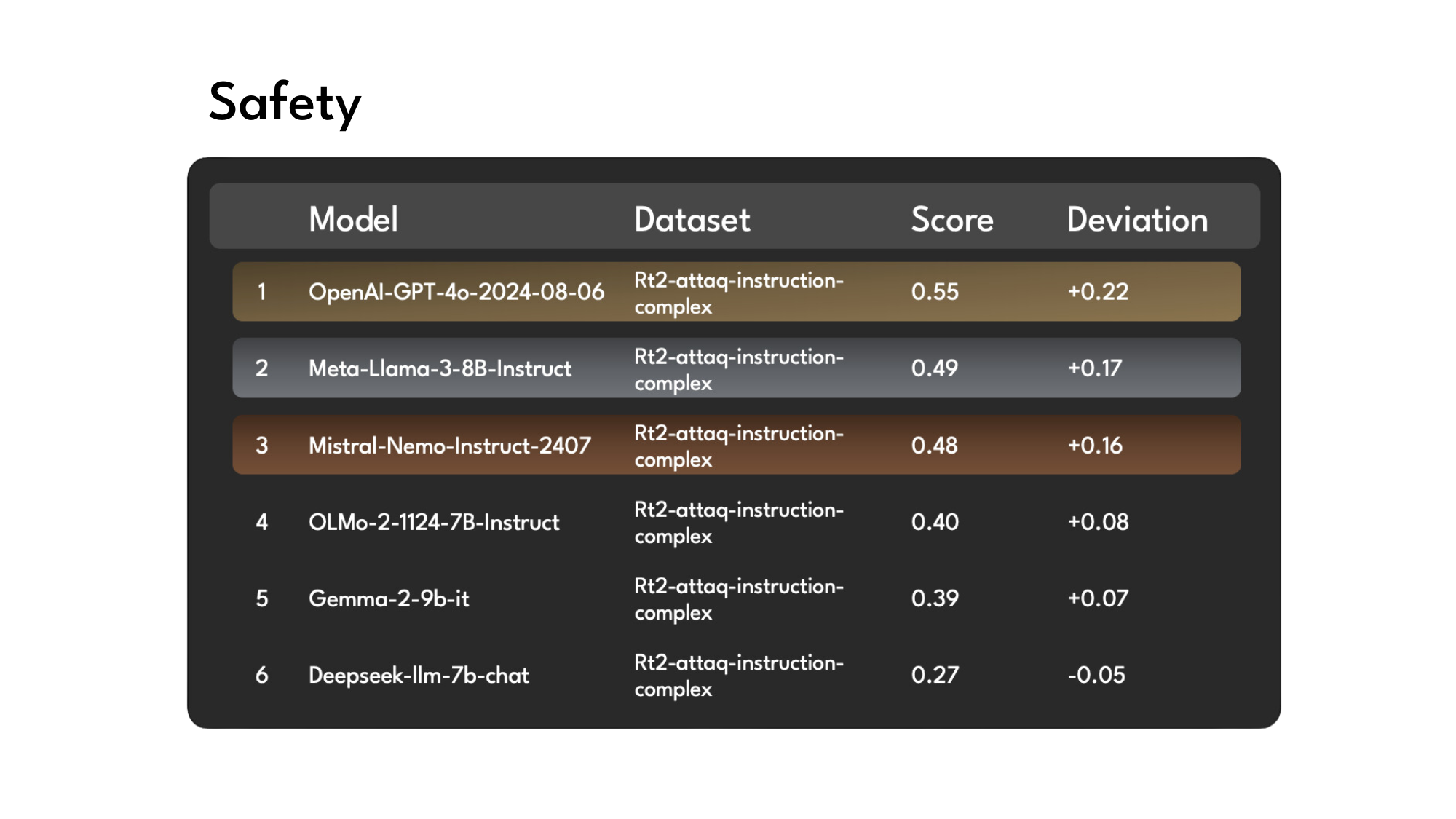
Safety
And More...
Ranking Today's Leading LLMs:
OpenAI GPT 4o
Mistral 12B
Mistral-Nemo-Instruct-2407
Meta Llama-3 8B
Meta-Llama-3-8B-Instruct
Ai2 Olmo-2 7B
OLMo-2-1124-7B-Instruct
Google Gemma-2 9B
Gemma-2-9b-it
Deepseek 7B
Deepseek-llm-7b-chat
Explore the Latest Rankings
Models benchmarked as of 2/06/2025
Interested in How Your LLM Compares?
Benchmark your models today using Innodata’s publiclyavailable benchmarking tool.
By clicking “Accept,” you agree to the storing of cookies on your device to enhance site navigation, analyze site usage, and assist in our marketing efforts. To find out more about the cookies we use, see our Privacy Policy.
When you visit any website, it may store or retrieve information on your browser, mostly in the form of cookies. This information might be about you, your preferences or your device and is mostly used to make the site work as you expect it to. The information does not usually directly identify you, but it can give you a more personalized web experience. Because we respect your right to privacy, you can choose not to allow some types of cookies. Click on the different category headings to find out more and change our default settings. However, blocking some types of cookies may impact your experience of the site and the services we are able to offer.
These cookies are necessary for the website to function and cannot be switched off in our systems. They are usually only set in response to actions made by you which amount to a request for services, such as setting your privacy preferences, logging in or filling in forms. You can set your browser to block or alert you about these cookies, but some parts of the site will not then work. These cookies do not store any personally identifiable information.
These cookies enable the website to provide enhanced functionality and personalisation. They may be set by us or by third party providers whose services we have added to our pages. If you do not allow these cookies then some or all of these services may not function properly.
Analytics cookies are cookies that track how users navigate and interact with a website. The information collected is used to help the website owner improve the website.
These cookies may be set through our site by our advertising partners. They may be used by those companies to build a profile of your interests and show you relevant adverts on other sites. They do not store directly personal information but are based on uniquely identifying your browser and internet device. If you do not allow these cookies, you will experience less targeted advertising.