

Lessons Learned from Creating Annotated Datasets for NLP
Natural language processing (NLP) may very broadly be defined as the automatic processing and analysis of large amounts of language data by software. With the evolution and democratization of artificial intelligence and machine learning (AI/ML),as well as data-driven methodologies and the ample availability of large amounts of online digital data, new sets of NLP tools have emerged and become largely mainstream. However, the key pre-requisite to build applications leveraging these tools and technologies is the availability of highly relevant representative data. Due to this dependence on the context, relevance, quality and availability of a good number of examples to work from there is often a big challenge in creating meaningful datasets.
Innodata has been working on an ML-driven data annotation platform which can input a PDF (such as a derivative contract or a scientific journal) and output a tagged XML file.This article is intended to illustrate our experience building the datasets to train the underlying ML models. We previously shared the challenges we encountered during the creation of the zoning datasets. In this piece we dig deeper into the journey of creating datasets through data annotation and discuss the challenges encountered and lessons learned.
Recap
The ultimate goal of the our data annotation platform is to create a fully annotated XML file from a PDF. The data extraction happens in the following stages:
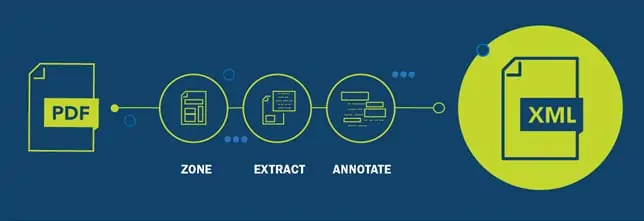
We have already created a zone dataset and created microservices which can zone PDF documents. We created OCR (optical character recognition) components and used PDF extraction to extract text from these zones. The next step was to create a model which can tag the text extracted from these zones. To train this model we needed a tagged XML dataset. Sounds easier enough, right? But here is where the challenge lied.
Mining Available Data
As a first step we started scouring for annotated datasets from prior Innodata projects. The most logical place to look for annotated data were from projects from similar domains where we wanted work. However, data from many of these projects were not directly usable.
We identified a particular project which seemed to be best suited to serve our data needs.
- Project running since 2011
- More than 23,000 documents digitized, analyzed and ingested in system covering more than 30,000 counterparties
- Comprehensive data model with around 1,200 data points making access, search and reports easy
- Trained SME’s well versed with the domain
When we identified the project, initially we thought that we did not need to look any further since we had such a massive amount of data available to us.However, as we dived deeper into the data, we realized it was not in the format that was needed.
The following are some of the main challenges that we faced with this particular dataset:
Data was mix of presentation logic and data
The data that we had was a mish-mash of presentation as well as some business logic built into it. It also had data elements which were sourced from other foreign databases by SME’s. Using this data to train ML models would necessitate writing complex pre-processing logic and subsequently testing the validity of data after cleaning.
During the time that this project was being done, we did not have a concrete data strategy in place. The end-goal of the development teams were to deliver tagged XML’s to the customer. This XML was also used in an analytics application for searching through tags. Some presentation and styling logic was frequently inserted into the data.

Ex : HTML Tags /Presentation is embedded in data: datapoints cannot be extracted from tables/tr/td and other presentation tags
Very Complex Schema
Our platform schema was quite multifaceted, consisting of a multi-level hierarchical structure. It had many levels of nested elements. Finding patterns and extracting relevant data points from complex schema requires a massive pre-processing effort. Therefore, this data was very complex for training our models. Ideally, for training a model, a flat data structure makes the most sense and makes the job easier. Business logic embedded in the data
Business logic embedded in the data
This data had numerous extra elements that were added in order to build business logic to show it in an analytics tool. This data was an interpretation of the text and not a direct reference. External sources and domain knowledge were used to create these data points. This data is not relevant as ML cannot apply business logic.
Moreover, the additional information in the data (presentation, business logic and external data) just adds to the noise in the data and is not helpful in training ML models.
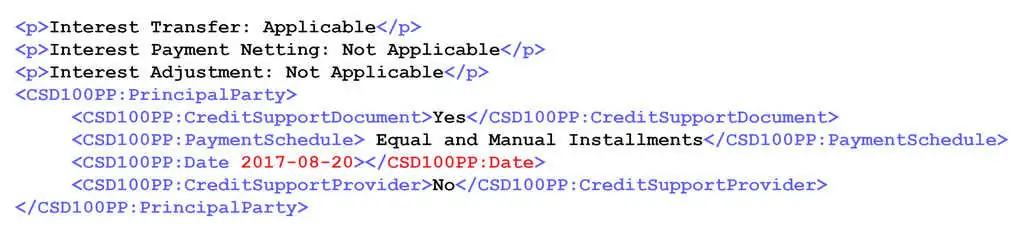
Co-ordinate information was missing
The annotated data did not have co-ordinate information for the various text elements. In our use case, co-ordinate information was needed to navigate to a support paragraph for tagging. We also found that the dataset had co-ordinate information but was later stripped off as it was not found to be useful for the original end product.
Inconsistencies in class names
This data was produced over many years. The dataset and taxonomy had evolved over time. Therefore, there were inconsistencies in terms of class names.
Data elements in tags
Many data elements were contained within
tags, without data point names. It was difficult to extract data elements and make sense without data point names. The data also had zone names used in the data – which was subsequently being used to drive the presentation. Leaving these in the data would increase pre-processing tasks exponentially.

For best ML results, the training dataset should be consistent, in a clean format,in a simple structure and should contain only the most relevant data.
The solution
The current dataset had more than 1,500 data points. The data points were not consistent across all documents. We decided to identify the most frequently used data points for iteration 1.
We had our SME’s work through all these and identify the top data points. After a few iterations, we narrowed it down to about 800 data points.
The existing dataset had a complex schema and multi-level hierarchical data. Using the data in the given hierarchy would have created additional challenges in producing efficient ML models. Therefore, we decided to transform our data to a flat model. With this, we would have additional advantage of de-coupling the structure of data to an external system which could be more adaptive to future changes in business needs. The idea was that the model would predict a flat XML structure and the consumer of this data would apply the required transformation logic on this data to structure it to any XSD (XML Schema Definition)that they wanted.
Iteration One
After several rounds of analyzing the data, we devised a strategy to transform the data to our desired format and also to strip out the additional unwanted data elements. We wrote transformation and cleaning scripts and processed a small set. However, due to the noise in the data, we needed a thorough QA process. After a few rounds of QA, we concluded that performing QA on the transformed data would be a much more time-consuming process compared to creating fresh data from scratch.
Iteration Two
We already had a workbench in the data annotation platform for data tagging. We created the business taxonomy in the format that we wanted. We employed a few of our internal lawyers (SME’s) for data preparation and trained them on our workbench and taxonomy.
It took us about two weeks to get the first dataset ready (about 50 contracts). Once this was ready, we trained our model with this small set. Having trained with a small set gave us an advantage that the next set of data was tagged by the model (though not always correct). After the initial training the SME was expected to correct and tag the missing pieces only. Today, this is an ongoing process and as we proceed, we expect the model efficiency to improve further.
Key Takeaways
Data science or AI/ML is heavily dependent on quality, not quantity. After studying data from several projects, here is our assessment of the current data landscape in most organizations:
- Companies have large amounts of data
- Data is a mish-mash from different sources
- There is no concrete data strategy in place until it is too late
- Projects store data according to specific project needs
That said, here are the key takeaways from our data acquisition journey:
- The data sets need to be representative of the reality and must be of good quality.
- This kind of off-the-shelf data is often non-existent in enterprises.
- Curating these data sets requires a data strategy to be in place and requires discipline as well as resources to execute.
- Data should be collected in a raw format.
- Any transformations (like presentation logic and business logic in our case) must be segregated and not mixed with the underlying data.
- Surrogate or external data should also be persisted separately.
Have you experienced similar challenges? We’re hopeful the lessons we learned will help you as you look to build datasets for your AI/ML initiatives.