

Quick Concepts
What is Knowledge Distillation in AI?
As AI models grow increasingly complex and resource-intensive, the need for efficient solutions becomes paramount. Large language models, while impressive, often come with a hefty computational cost. Knowledge distillation is a promising solution to compress large models without compromising performance. By transferring knowledge from a larger, more complex model to a smaller, more efficient one, this technique enables the deployment of AI in resource-constrained environments.
What is Knowledge Distillation?
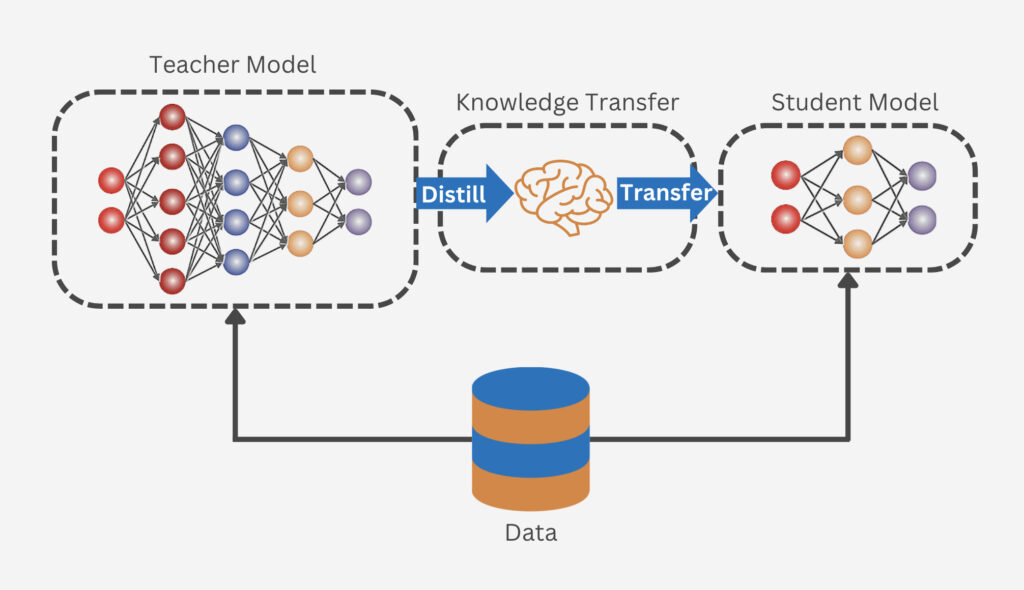
Knowledge distillation is a process where a smaller, more efficient model, known as the “student model,” is trained to replicate the behavior of a larger, more complex model, called the “teacher model.” This technique is primarily used to compress large models into smaller ones that are faster and more cost-effective while retaining much of the original model’s accuracy and capabilities.
The essence of knowledge distillation lies in its ability to transfer the “knowledge” from the teacher model to the student model. Instead of learning directly from the original training data, the student model learns to mimic the outputs of the teacher model. This process allows the student model to learn not just the final predictions of the teacher model but also the underlying patterns and nuances, leading to a more efficient learning process.
Why is Knowledge Distillation Important?
In many practical applications, the size and complexity of AI models can be a significant barrier. Large models, while powerful, are often too resource-intensive for real-time or edge deployment. Knowledge distillation addresses this challenge by creating smaller models that can perform similarly to their larger counterparts but with significantly reduced computational requirements.
For instance, imagine trying to run a complex AI model on a smartphone. It might be too slow or crash due to the device’s limited power. Knowledge distillation can help by creating a smaller, more efficient version of the model that can run smoothly on the phone. This makes AI more practical for everyday devices, like smartphones and internet-connected gadgets, and helps everyone have access to the benefits of AI technology.
How Does Knowledge Distillation Work?
The process of knowledge distillation involves training the student model to match the outputs of the teacher model. This is achieved through the use of a specialized loss function that measures the difference between the outputs of the two models. There are several ways in which this knowledge can be distilled:
- Response-Based Knowledge Distillation: This is the most common method, where the student model is trained to replicate the final output layer of the teacher model. The student learns to match the teacher’s predictions, often using a technique called “soft targets,” which provides more nuanced information than traditional hard targets.
- Feature-Based Knowledge Distillation: This approach focuses on the intermediate layers of the teacher model. By training the student model to replicate the features learned by these layers, the student can learn to extract similar patterns from the data, enhancing its performance.
- Relation-Based Knowledge Distillation: This method goes a step further by training the student model to understand the relationships between different parts of the teacher model. By mimicking these relationships, the student can better emulate the complex reasoning processes of the teacher.
Applications of Knowledge Distillation
Knowledge distillation is widely used across various domains, such as NLP, computer vision, and speech recognition. A notable application is the development of Small Language Models (SLMs), which are designed to be more efficient and compact than their larger counterparts, LLMs. SLMs created through knowledge distillation can perform tasks like text generation and translation while requiring significantly less computational power, making them ideal for deployment on devices with limited resources.
Additionally, knowledge distillation enhances the explainability of AI models. Smaller models are often easier to interpret, which is particularly valuable in sectors like healthcare and finance, where understanding how AI makes decisions is crucial. By creating streamlined models that retain high performance, knowledge distillation supports the development of AI solutions that are both effective and transparent.
Limitations of Knowledge Distillation
While knowledge distillation offers significant advantages in creating efficient AI models, it is not without its challenges. Here are some key limitations to consider:
- Performance Limitations: The performance of the student model is inherently tied to that of the teacher model. If the teacher model has limitations, such as struggles with specialized tasks, the student model will likely inherit these shortcomings. This can result in suboptimal performance for specific applications where highly specialized accuracy is required.
- Data Requirements: Despite its efficiency, knowledge distillation still requires a substantial amount of data. The student model learns from the teacher’s outputs, which means the quality and volume of data used to train the teacher model are crucial. Insufficient data can hinder the effectiveness of the distillation process.
- Data Accessibility: In some cases, organizations may face restrictions on using certain datasets, particularly when dealing with sensitive or proprietary information. This can pose a challenge if the data needed to train the teacher model is not available or cannot be used due to privacy or contractual constraints.
- API and Licensing Restrictions: When using large language models (LLMs) through third-party APIs, there may be licensing or usage restrictions that prevent the output from being used to train new models. These restrictions can limit the ability to leverage LLMs for distillation if the API terms prohibit such uses.
The Future of Knowledge Distillation in AI
Knowledge distillation is a transformative technique that enables the creation of smaller, more efficient AI models without sacrificing performance. By transferring the knowledge from a larger, more complex model to a streamlined version, it reduces computational requirements and makes advanced AI technologies more accessible and practical for a wide range of applications. As AI continues to evolve, the ability to deploy powerful models in resource-constrained environments will become increasingly important.
For businesses looking to leverage AI’s potential while minimizing costs, knowledge distillation offers a compelling solution. By understanding and applying this technique, organizations can drive innovation, efficiency, and growth. At Innodata, we empower leading tech companies, enterprises, and AI/ LLM teams to achieve their goals and stay ahead of the competition. By partnering with us, you gain access to unmatched data quality and subject matter expertise. Contact an Innodata expert today to learn more.
Bring Intelligence to Your Enterprise Processes with Generative AI

Whether you have existing generative AI models or want to integrate them into your operations, we offer a comprehensive suite of services to unlock their full potential.
follow us