

What is the Difference Between RLHF and RLAIF?
Large language models (LLMs) capture imaginations and spark debates with their remarkable abilities. But unleashing their full potential demands alignment with our goals and preferences. Here, two approaches arise: human-powered Reinforcement Learning from Human Feedback (RLHF) and AI-driven Reinforcement Learning from AI Feedback (RLAIF). Both leverage feedback loops within Reinforcement Learning (RL) to steer LLMs toward fulfilling human intent, but their mechanisms and implications differ dramatically. Grasping these differences is important for businesses harnessing LLMs in the real world.
What is RLHF?
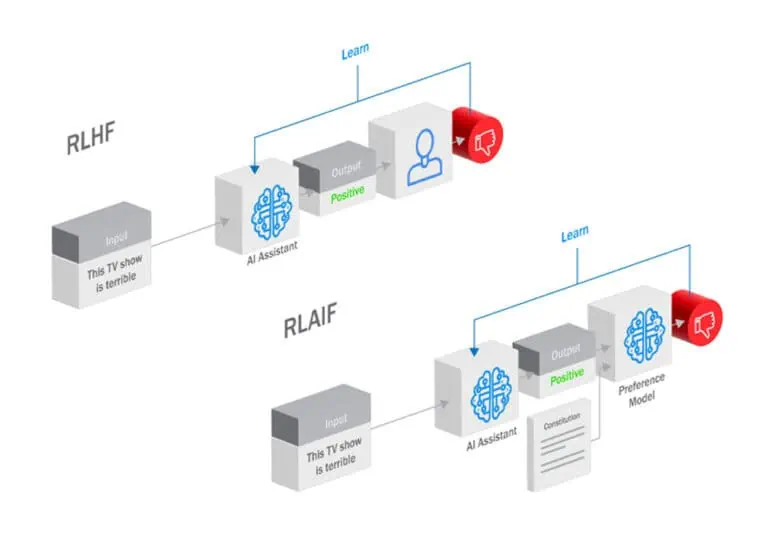
RLHF is a process that bridges the gap between AI model capabilities and human desires. It involves a feedback loop where the model generates outputs, humans evaluate these outputs, and their evaluation informs the model’s future generations. This iterative process leads to outputs increasingly aligned with human expectations and values.
The feedback from humans, who provide their expertise or domain knowledge, forms the backbone of a “preference model.” This model guides the reinforcement learning process of the AI agent. The feedback can take various forms, including explicit instructions, demonstrations, or evaluative feedback on the agent’s actions.
By rewarding outputs that align with human preferences and penalizing those that deviate, the AI agent gradually learns to adapt its behavior accordingly. One of the key advantages of RLHF is its ability to leverage human intuition and expertise, especially in complex domains where explicit reward signals may be challenging to define. RLHF accelerates the learning process and enables AI agents to make more informed decisions.
Benefits of RLHF
- High degree of human control: RLHF allows businesses to directly influence the LLM’s output, ensuring it adheres to specific brand guidelines, ethical considerations, or task-specific requirements. This is especially beneficial for tasks that require a high degree of accuracy or sensitivity, such as writing legal documents or generating medical advice.
- Interpretability and explainability: Human feedback provides a clear line of sight into the LLM’s decision-making process, making it easier to understand and troubleshoot potential biases or errors. This is important for building trust in LLMs and ensuring that they are used responsibly.
- Proven effectiveness: RLHF has demonstrated success in numerous applications, from improving the factual accuracy of news articles to fine-tuning chatbots for customer service.
Challenges of RLHF
- Scalability limitations: Gathering and annotating large amounts of human feedback can be expensive and time-consuming, hindering LLM development for large-scale projects.
- Subjectivity and bias: Human feedback can be inherently subjective and biased, potentially skewing the LLM’s learning process and introducing unwanted biases into its outputs.
- Resource dependency: RLHF relies heavily on human expertise and resources, which may not be readily available or affordable for all businesses. This can make it difficult for small businesses or startups to take advantage of the benefits of LLMs.
What is RLAIF?
While RLHF excels in harnessing human expertise, its dependence on human resources presents limitations. Enter Reinforcement Learning from AI Feedback (RLAIF), an approach that automates the feedback loop by leveraging the capabilities of another AI model. This “preference model” acts as a surrogate for human evaluators, providing the AI agent with guidance based on its understanding of human preferences and values. RLAIF closely mirrors the RLHF training approach, with the primary distinction being that the feedback originates from an AI model instead of human evaluators.
Imagine a scenario where you’re training a chatbot to answer customer queries. With RLHF, you’d need human annotators to assess the chatbot’s responses and provide feedback. RLAIF, however, empowers you to train a separate AI model that can analyze customer satisfaction data, social media sentiment, and other relevant signals to automatically assess the chatbot’s performance and offer feedback for improvement.
Benefits of RLAIF
- Scalability: RLAIF eliminates the bottleneck of human feedback, making it ideal for large-scale LLM development and training.
- Reduced Bias: By relying on data-driven insights, RLAIF can mitigate human biases and lead to more objective and unbiased LLM outputs.
- Cost-Effectiveness: Automating the feedback loop significantly reduces the need for human resources, leading to cost savings in LLM development and deployment.
- Continuous Learning: The AI preference model can continuously learn and evolve, adapting to changing human preferences and values over time.
Challenges of RLAIF
- Dependency on the coach LLM: The effectiveness of RLAIF hinges on the quality and alignment of the coach LLM with the desired LLM behavior. Choosing and training the right coach LLM can be a complex and challenging task.
- Model Training: Training the AI preference model effectively requires access to high-quality data and robust learning algorithms.
- Interpretability and explainability: Understanding the AI-based feedback generated by the coach LLM can be challenging, potentially hindering debugging and addressing potential biases.
- Ethical Considerations: The use of AI for feedback raises ethical concerns about transparency, accountability, and potential misuse.
Which Solution is Best?
When it comes to selecting between RLHF and RLAIF, there is no one-size-fits-all solution. The choice depends on various factors such as business objectives, target audience demographics, linguistic requirements, and budget constraints. Here are some considerations to help you make an informed decision:
- Content Standardization vs. Adaptation: If your primary goal is to maintain consistency and quality across all your content assets, RLHF may be the ideal choice. However, if you’re targeting diverse global markets and need to adapt your content to local languages and cultures, RLAIF offers the flexibility and customization you need.
- Scalability and Integration: Consider the scalability of the solution and its compatibility with your existing content management systems and workflow processes. RLHF may be more suitable for large-scale content operations with standardized language requirements, while RLAIF excels in global integration and multilingual support.
- Budget and Resource Allocation: Evaluate the cost-effectiveness of each solution in terms of initial investment, ongoing maintenance, and resource allocation. While RLHF may require a higher upfront investment in technology and customization, RLAIF’s pay-as-you-go model and flexible pricing options may be more suitable for businesses with budget constraints.
- Future Growth and Innovation: Anticipate your future growth trajectory and the evolving needs of your target audience. Choose a solution that can adapt and scale along with your business, incorporating new technologies, languages, and market trends seamlessly.
| Feature | RLHF | RLAIF |
|---|---|---|
| Feedback Source | Humans | AI Model |
| Scalability | Limited by human resources | Highly scalable with readily available data |
| Subjectivity & Bias | Prone to human biases | Can mitigate human biases through data analysis and model training |
| Resource Dependency | Requires significant human expertise | Can operate with minimal human intervention |
This is where Innodata steps in, not only as a data management and AI leader but as your trusted partner in unlocking the full potential of generative models. Our expertise extends beyond simply providing high-quality training data. We offer a comprehensive service portfolio encompassing both RLHF and RLAIF solutions, tailored to your specific needs and objectives.
Whether you prioritize human control and interpretability through RLHF or seek the scalability and cost-effectiveness of RLAIF, Innodata guides you through your AI journey. Contact us now!
Bring Intelligence to Your Enterprise Processes with Generative AI

Whether you have existing generative AI models or want to integrate them into your operations, we offer a comprehensive suite of services to unlock their full potential.
follow us