

Your Model Performance Problems are Likely in the Data
Over time data has become devalued and overlooked in the AI development process, despite numerous warnings by experts
Why you need to rethink model development
When people think about artificial intelligence their mind is often filled with images of a futuristic world where algorithms power robots that take care of their daily responsibilities; their virtual assistant offers them advice and manages their schedule; cars drive them around while they nap or watch a movie. Data scientists and machine learning engineers think about the glory of developing the next cutting-edge model or discovering a change to the algorithm that will boost performance. What most people don’t immediately think about is the most important part of building an AI or ML model, and that’s the data used to train it.
Everyone wants to do the model work, not the data work
Experts consistently recommend that data scientists and AI developers focus on acquiring, cleaning, and preparing their datasets from the outset of a project. Still most AI teams skip to building or selecting their algorithm, choosing their ML platform, and determining the best programming language for AI. The data is pushed aside and often forgotten.
In fact, in a paper recently published on Google Research, researchers at ACM SIGCHI, a leading international community of professionals interested in the practical application of human-computer interactions, consider data to be “the most under-valued and deglamorised aspect of AI.”
Your problems are likely in the data, not the model
When data science teams run into problems with their models, they are quick to blame computing power, lack of data, an issue with the algorithm’s architecture, or a lack of tools and resources. So, investment is often misplaced into those buckets, while data scientists tinker with the algorithm and change the model.
However, the experts at SIGCHI note two things:
- “Data largely determines performance, fairness, robustness, safety, and scalability of AI systems”
- “Currently data quality issues in AI are addressed with the wrong tools created for, and fitted to other technology problems.”
With that being that case, it is usually not model issues stopping your AI goals and dragging down model performance. It is your data causing the problems.
Consider your data from the start or lose valuable time
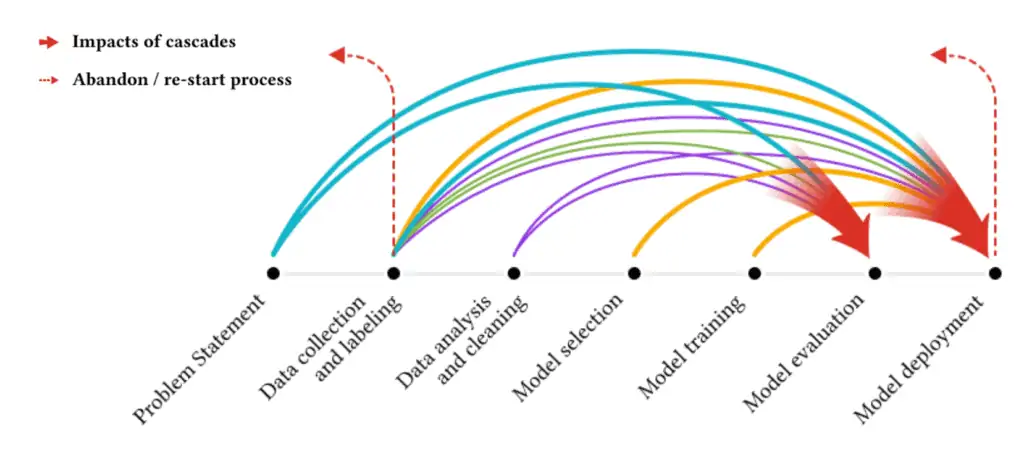
Time then must be taken to dig into the data and figure out why it is causing poor performance. This is a common occurrence, causing timelines to extend and frustrations to rise. Experts have identified a few of the reasons for these problems including, “misaligned incentives and priorities between practitioners, domain experts, and field partners, and limited budgets for data collection.” In some cases, the cause of data issues is “poor cross-organisational documentation leading to missing metadata causing practitioners to make assumptions, ultimately leading to costly discarding of datasets or re-collecting data.” With that in mind, data, which is fundamental to model success, must be part of initial project planning. The effects from the data collection and preparation cascade and impact the model deployment.
Data Scientists may not be data preparation experts
Numerous data issues can arise from low quality annotations, bias in the datasets, or lack of specialized data to fit your model goals. In some cases, “AI practitioners were responsible for data sense-making (defining ground truth, identifying the necessary feature sets, and interpreting data) in social and scientific contexts in which they did not have domain expertise.” Clearly, not fully understanding the context of the data would lead to quality issues. What’s worse is not only can it lead to poor data quality, according to a survey of data scientists, 80% of their time can end up going toward data preparation. Which means a lot of time is spent for poor results.
Play to your strengths and choose the right provider
So, how does an AI development team avoid or correct these problems? Employ data preparation experts. Seek data experts who have experience in the areas you’re developing your models to work in. For example, not all data preparation experts have subject matter experts available to provide proper context for your annotations. Innodata has over 3,500 in-house SMEs with advanced degrees across healthcare, sciences, finance, and law. Innodata offers an end-to-end training data solution, providing data collection and annotation services to ensure you get the ground truth data you need for your models to succeed.
Bring Data to the forefront of your AI Plans
To have success in your AI projects it is critical to understand your needs from the outset. The research done by SIGCHI shines a light on “the need for data excellence in building AI systems, a shift to proactively considering care, sanctity, and diligence in data as valuable contributions in the AI ecosystem.” Moving forward, take the advice of all the experts stop devaluing data and put at the forefront of model development.
Consider choosing data preparation experts to fill the gaps in your process and team to deliver the highest quality data for training your models. Not only will that free up your scientists to focus on the model development work that they want to do, it will reduce the amount of rework necessary, and speed up the time to production for your model.
Accelerate AI with Precise
Annotated Data
Check out our whitepaper on 5 questions to ask before getting started with data annotation