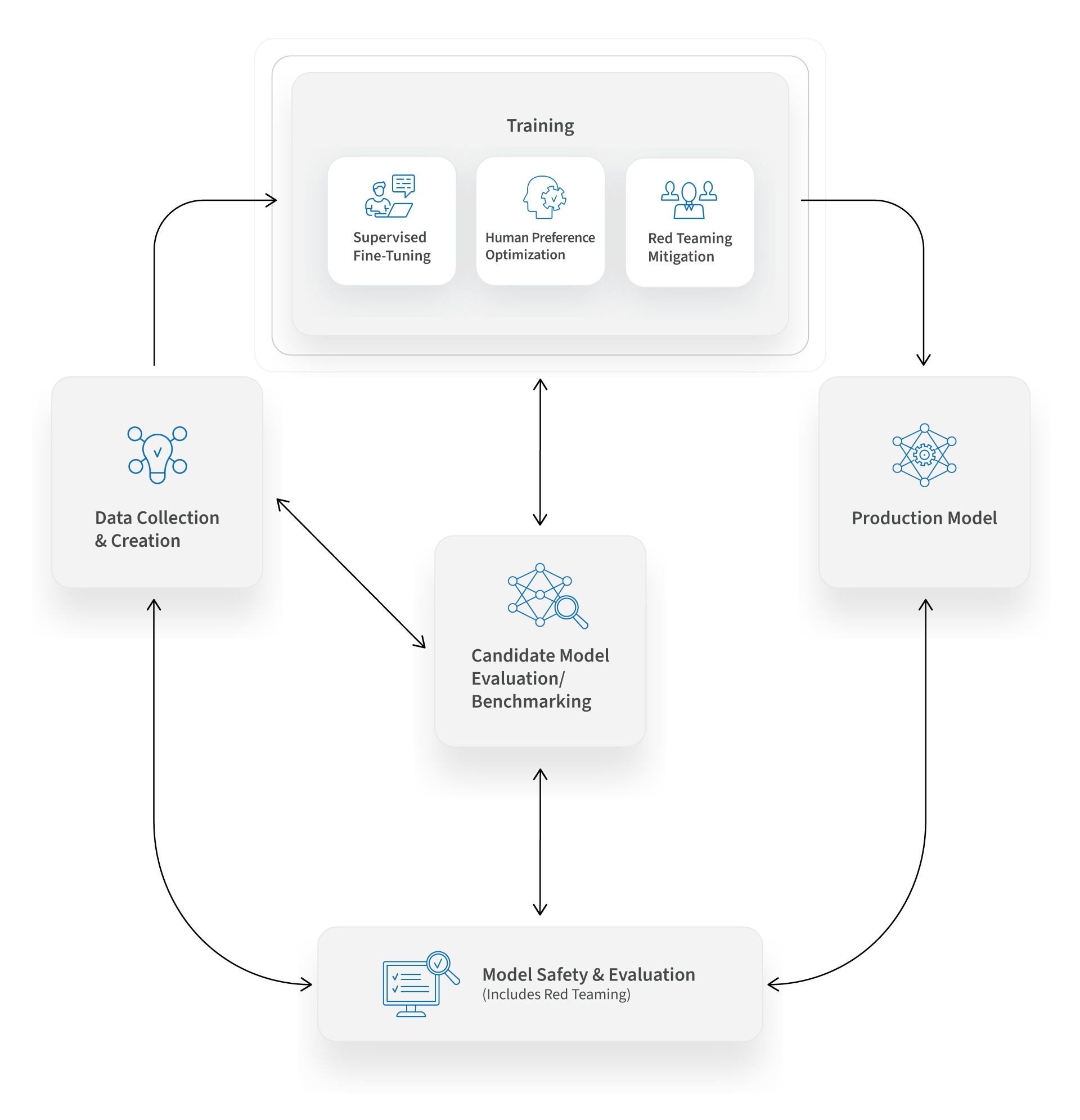
Ensure the reliability, performance, and compliance of your generative AI models. Assess model performance using task-specific metrics to gauge accuracy and identify potential improvements, then allowing for improved accuracy with new data.
Address vulnerabilities with Innodata’s red teaming experts. Rigorously test and optimize generative AI models to ensure safety and compliance, exposing model weaknesses and improving responses to real-world threats.