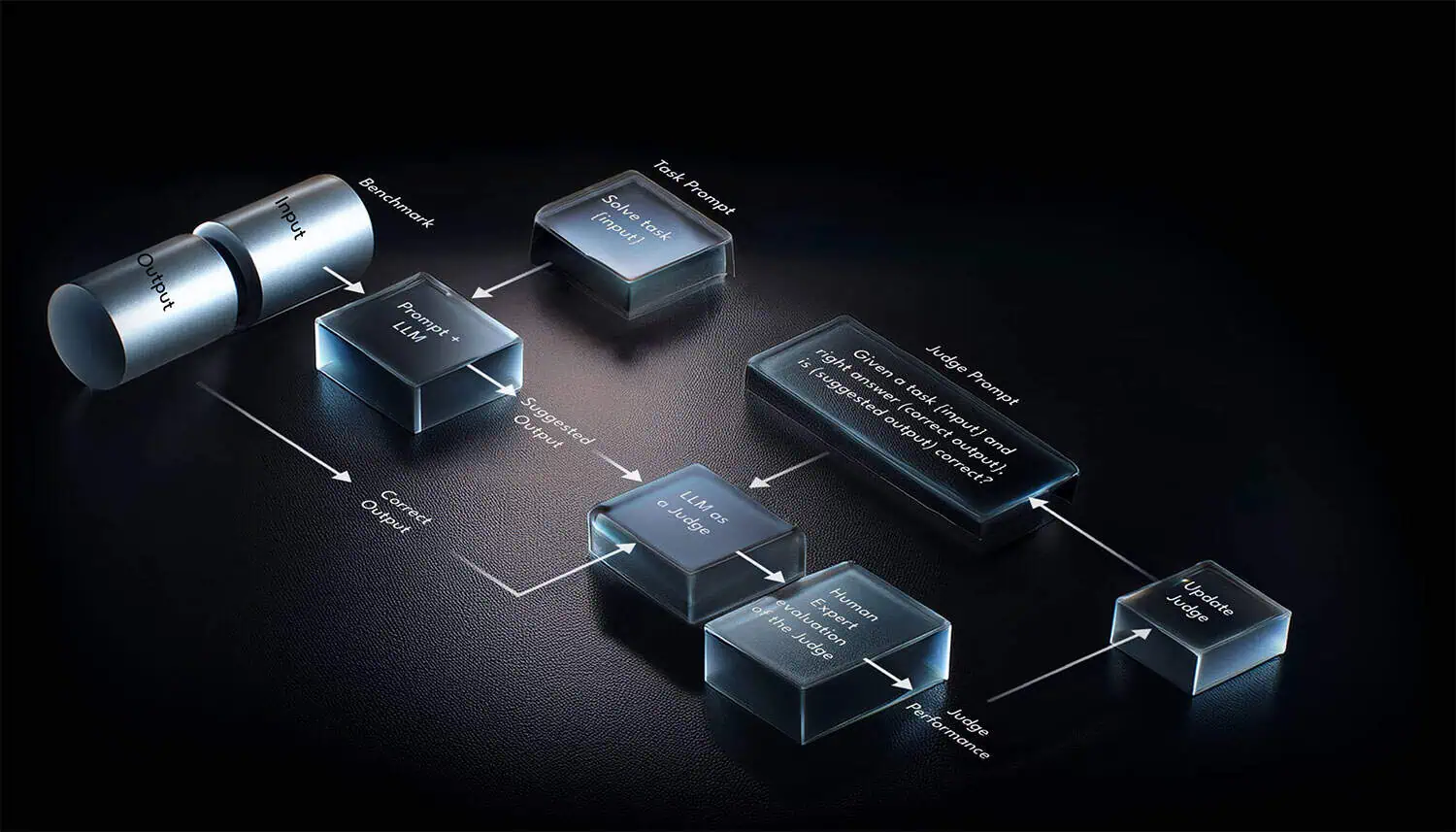




Proven LLM QA Expertise
- 87M+ LLM labels delivered YTD across 15+ GenAI workflows
- Specialists in hallucination detection, groundedness scoring, brand alignment compliance, and refusal analysis
- Repeatable QA metrics to inform model tuning and roadmap alignment.
- Structured QA frameworks for copilots, agents, RAG, and embedded LLMs—adapted for task and product context
- Data-driven insights that inform model tuning, prompt optimization, and roadmap alignment
Hybrid QA Model
- 87M+ LLM labels delivered YTD across 15+ GenAI workflows
- Specialists in hallucination detection, groundedness scoring, brand alignment compliance, and refusal analysis
- Repeatable QA metrics to inform model tuning and roadmap alignment.
- Structured QA frameworks for copilots, agents, RAG, and embedded LLMs—adapted for task and product context
- Data-driven insights that inform model tuning, prompt optimization, and roadmap alignment
Global, Enterprise-Ready Delivery
- 87M+ LLM labels delivered YTD across 15+ GenAI workflows
- Specialists in hallucination detection, groundedness scoring, brand alignment compliance, and refusal analysis
- Repeatable QA metrics to inform model tuning and roadmap alignment.
- Structured QA frameworks for copilots, agents, RAG, and embedded LLMs—adapted for task and product context
- Data-driven insights that inform model tuning, prompt optimization, and roadmap alignment