

An Ode to a Document
When people ask me what I do for a living, I proudly answer: I drive technology innovation for a company that does Document Processing and Analysis. The reaction I receive is typically a blank gaze. Let me explain why Document Analysis is an exciting area of applied Computer Science research. To make my case I’ll explain what is a Text and what is a Document, and discuss the (often misunderstood) relationship between the two.
What is a Text?
Not so stupid a question, actually. Here by a Text, I understand the information presented as a linear sequence of characters. As an example, let me take a novel — Crime and Punishment by Fyodor Dostoyevsky — and print it in one long line. Using a 10pt font I’ll end up with a line 2 miles long! This is the Text.
Another familiar metaphor for a linear sequence is a reel of tape. You start at the beginning, and follow it till the end. A 10.5-inch reel of tape holds three-quarters of a mile of magnetic tape. I’ll need three reels to type Crime and Punishment on it!
Linear (meaning – sequential) model of text is very important.
- It is simple, which makes it easier to analyze. We all like to start tackling a hard problem with dumbing it down to the simplest case.
- Many documents are naturally represented as a sequence of characters (aka Text).
- It directly maps to many activities which are sequential in nature. For example, speech, or typing on a computer. Mapping between Text and these activities is easy and straightforward.
Last, but not least: a lot of research has been done by the academic community and industry to make sense of a Text. We can parse, find intent, detect sentiment, classify, translate and tag text with well-established and highly automated techniques.
What is a Document?
Here I will define a document as a practical way of storing information. Two miles long string is not practical, obviously. Three reels of tape is better, but still far from being convenient for the reader.
- Throughout history, mankind has invented many ways of storing information. Some of the most successful ones are: Uniform tablets, bark and cowhide scrolls, papyrus, milled paper, and, finally, bits in a computer memory.
- Specific limitations of the storage media gave rise to novel and interesting ways of laying out the textual information.
- Hyphenation was invented as a way to save space on an expensive parchment, and also to make justified text look more uniform and visually appealing.
- Multi-column layouts were introduced to make reading large books easier.
- Font art was created. Ornaments added. Visual language of charts, figures and illustrations was invented.
- Tables were introduced as a way to present complex information in a structured way.

Strictly speaking, a document cannot be reduced to a sequence of characters. Many important information is conveyed via geometry and purely visual cues.
And even if we put visual cues aside, we often see documents where textual information is not linear in nature.
Take a footnote as an example. One reader may always follow the footnote marks and read the footnote text before returning to the main text. Another may just ignore all the footnotes, or return to them later, after reading the main piece. Here we see that there is no “natural” way to represent a text with footnotes as a linear sequence. It is more like a tree: you can choose to follow a branch (and read the footnote text), or you may choose to follow the trunk, and ignore the footnote branches. The freedom this provides is precious – it gives to the reader a chance to use different reading patterns depending on the end goal and available time.
Another prominent example of non-linear information is a Table. It is clearly a two-dimensional structure. It does not make sense to linearize it. If you ask me to “read” a table a-loud, I will have a great difficulty. But by just looking at a table one can easily grasp the relationship between columns, rows, and cells. Tables are designed for visual processing!
Sometimes we have several independent information flows. Look at the front page of any newspaper. Where do we start reading? There are many articles, some continue on the other pages. Some places are “catching the eye” and prompt the reader to look there. But overall, one can read articles in any order. In this example we have several independent information flows. Layout does not mandate the order. There is no natural sequence here. If one article (with footnotes) is like a tree, then a newspaper page looks like a forest: pick your tree and follow it, then pick the next, and so on. Until you have no more trees, or run out of coffee.
For completeness, let me list interesting features of a Document that are not present in Text:
- Hyphenation (across line breaks, column breaks, page breaks, float breaks)
- Two-column and multi-column layouts
- Parallel and subordinate information flows: Footnote is a subordinate “branch”. Marginal marks are subordinate too, as they refer to something in the main text. Front page of a newspaper has parallel information flows (each article is an independent piece).
- Purely visual information: Charts, illustrations, dividers. One side effect of these is that text flow is often broken to make space for these relatively large blobs (these are called “floats” in typesetting lingo)
- Structured text: Tables, lists (and nested lists)
- Navigational cues: Page numbers, running headers, running footers, tables of content, miscellaneous indices


On top of that, document analysis is often complicated by imperfect document quality. I mean, as a human I can read and understand a fairly dirty scan. But automating this with guaranteed accuracy is notoriously difficult. Companies are built around solving just that (OCR – Optical Character Recognition). Not that this problem is solved, by a long stretch.
A 3-D Document Model
Generally, a Document is a collection of pages. Each page is a two-dimensional plane with certain width and height, where text and other information is laid out, in a way which is most convenient for human understanding.
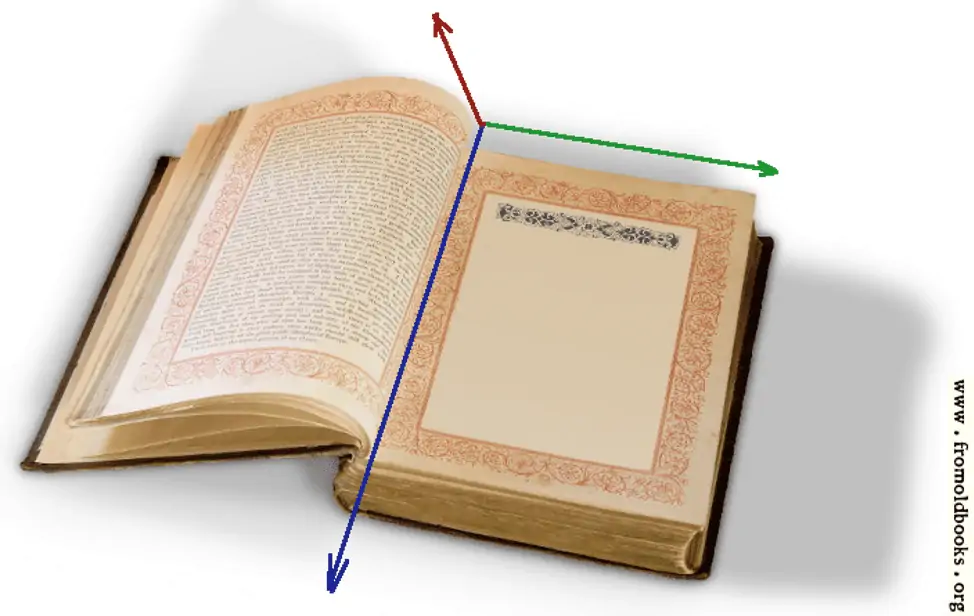
And we have three dimensions here! Each page is a two-dimensional object. And the sequence of pages makes the third (discrete) dimension.
The main difference between Text Processing and Document Processing is the object: a sequence of characters in Text Processing, and a sequence of 2-D pages in Document Processing. For the latter the “layout” and visual content may be as important as the text content.
The rules by which information is laid out make a “language”. This “document language” encompasses:
- Natural language (rules of spelling and grammar)
- Composition and layout language
- Visual textual features (how to align, emphasize and structure the text)
- Language of charts, illustrations, tables, lists
To extract information from a Document, we need to understand the “language of Documents”.
Note that Natural language is a subset of Document language. But other Document language components are heavily visual in nature. We can learn the Document language only if we model Document as a 3-D object. If we first cast it to Text, we will lose all geometrical and visual information and won’t be able to understand Document in its completeness.
Progress, Gaps, and the Wind of Change
Hopefully now I convinced you, my patient reader, that a Document can be much more than a Text, and that many documents cannot be reduced to a pure Text (without losing some information).
Document Analysis is a branch of Computer Science dealing with information extraction from Documents. It has its own scientific forum – ICDAR – the International Conference on Document Analysis and Recognition. Last year it was held in Sydney, Australia and about 200 papers were presented there.
The largest Machine Learning forum (NeurIPS) is 10x larger. Understandable, as machine learning and artificial intelligence topics are hot and research is booming. Still, it is a bit disappointing to see the hard but important task of Document Analysis still lacking focus from researchers.
We see a lot of progress in Text Analysis. In fact, 2019 can be remembered as a year of NLP (natural language processing). Very successful models for Text Understanding, generation, and translation have been developed. Many make their ways to the industrial applications (for example, pre-trained BERT and GPT2 are quickly becoming standard tools for building products around text processing).
Another interesting development in technology is the further advance of Computer Vision, where cognition accuracy approaches (and sometimes exceeds) human abilities.
Why are we excited about this? Because Computer Vision gives us the technology to analyze document pages the way humans do – without first linearizing them to Text. We see that merging Computer Vision with Text Analysis (NLP) becomes technologically possible. The key enabler is the creation of end-to-end trainable pipelines that do not need conversion to the intermediate Text representation.
How Innodata Approaches the Document Analysis Problem
The research team at Innodata recognizes that in the real world the processing unit is a Document, not Text. Before applying the latest successful text understanding models (think Neural Nets here), we need to deal with complex real documents of variable quality. Over the years we’ve developed technology that helps us to handle:
- Non-perfect document quality
- Recognize and strip off the “page matter”: running headers, running footers, page numbers
- Intelligently deal with hyphenations, including the ones that happen across column breaks and page breaks
- Sophisticated table parsing tooling
- We developed vision-based technologies to spot important parts of a document and focus on them
Our well-trained and dedicated SMEs (Subject Matter Experts) help us to cover hard cases where technology still falls short. The right balance between humans and technology allows us to ensure high quality, while keeping costs low.
Innodata’s Data Digitization Platform is a technology-first, API-driven processing pipeline, that integrates Machine Learning microservices and can recognize hard documents and yield to human judgement. It enables rapid research-to-production cycle and automatically collects feedback from SMEs to improve automation.
Human-Computer Interaction and a Cabbage Pie
Document understanding (when cracked) will also change how people interact with computers.
When I sit with my daughter and read a book to her, we just both look at a page, enjoying the colorful illustrations, nicely typeset text and the intricate ornament.
But when I need to feed a page of to a computer, the pain starts: I run it through my scanner, then run the image through an OCR program, then review and fix some occasional errors. If there was a table, I would likely have to reformat it so that it looks readable, etc. All highly tedious and fairly technical.
This barrier has to go. At some point we should be able to just show a grandma’s recipe to our kitchen robot and it will happily follow the instructions to produce that yummy cabbage pie.
Back from the Jetson’s world… Seriously, there is a huge gap in the level of Text comprehension and Document comprehension. Technology progressed impressively on the former, but not the latter. What companies like Innodata are doing is bridging this gap, dealing with Documents, and converting them to Digital Documents, using Text processing techniques along the way, and humans standing by to cover what technology cannot yet accomplish.
Again, there are strong indications that a major technological break-through in the Document Understanding is coming, due to the merging of Computer Vision and NLP techniques.
And if you are wondering if this technology change is going to wipe off Innodata’s customer base, leave your worries behind! We are not worried. To stay relevant in the future we strive to be on the technology forefront. We are experts in Document Analysis and Processing, and this skill will always be in demand.
If you happen to have a collection of documents and need to make sense of them, give us a call. We know how to handle documents of varying difficulty levels, and will process yours with care and love!
