

Self-Driving Cars Are Stuck In Park Without This...
To push autonomous vehicles into gear, ML teams need more than big data – they need smart data. This means investing in sophisticated tools to annotate image, video, and sensor data and acquiring expertise to make critical judgements that inform safe behavior on the road.
Big data is just the start for autonomous vehicle performance
The development and training of autonomous vehicles requires a massive amount of data that is fed into multiple systems such as long-range radar, LIDAR, short-range radar, ultrasonic sensors, and cameras. These systems must all work together simultaneously for the vehicle to navigate efficiently, effectively, and safely. As more and more companies undertake autonomous vehicle efforts, data is being collected at scale and open-source datasets for autonomous driving are being made available by Waymo, MIT, and Toyota.
And yet, even with the abundance of domain specific data, autonomous driving is not necessarily right around the corner. The process for making all this data usable for training autonomous driving is extremely complex because each system requires different types of annotation, a multitude of subjective judgements, and 99% accuracy.
Why AV requires more than just a large volume of data
When thinking about machine learning and artificial intelligence projects, conventional wisdom claims these problems can be overcome by feeding the model larger volumes of data. However, with autonomous vehicles we are seeing that mass quantities of data are not enough. For example, Tesla has over 3 billion miles worth of data for their self-driving cars and are still only at Level 2 out of 5.
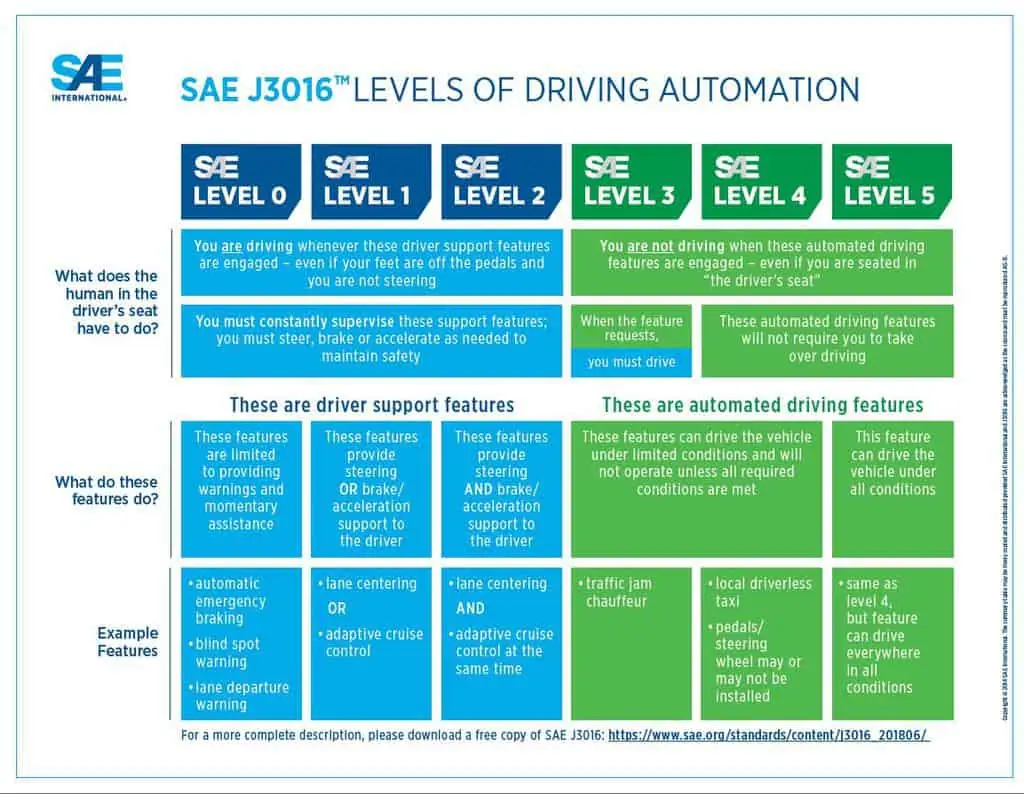
In the case of advancing progress on autonomous vehicles, smart training data may be more important than big data. This means knowing when to discard data. For example, you don’t want your model to adopt driving behaviors from a bad driver who cuts people off and tailgates. It means getting high quality annotations that provide proper context for the model to learn from. It means finding more and more edge case scenarios to teach the model, because driving mistakes can be a matter of life and death. So, not only is it important to collect enough data that includes a variety of scenarios to teach the model how to react to other drivers, that data must be thoroughly and properly annotated.
Types of annotations needed for smart training data
For powering the AI behind autonomous vehicles, multiple types of annotations are required. These include but are not limited to:
- Bounding boxes
- Semantic segmentation
- Object tracking
- Object detection
- Video classification
- Text annotation
- Sensor fusion
- Point cloud segmentation
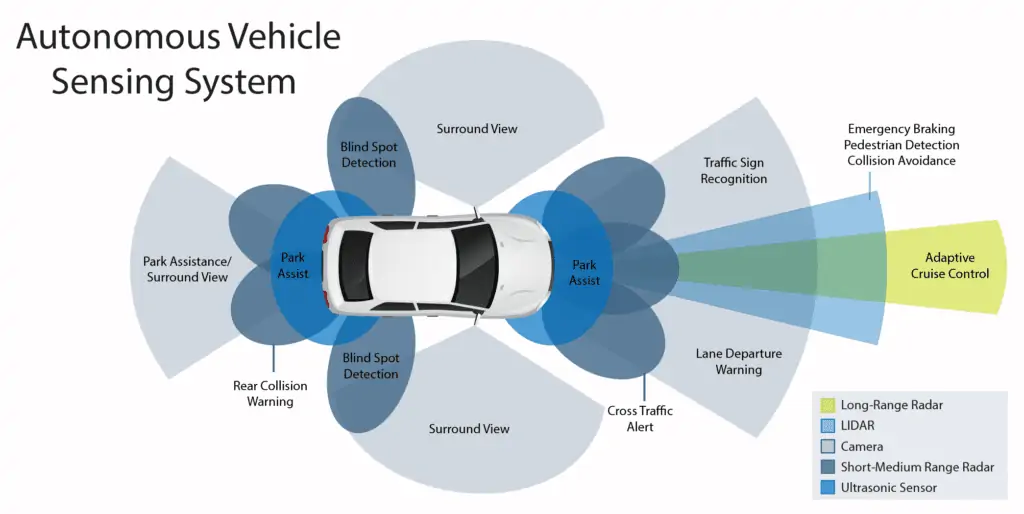
The ML models that drive autonomous vehicles must process and interpret data from multiple systems simultaneously. Cameras record 2-D and 3-D images and video. Radar is used for long, medium, and short-range distances using radio waves. Light detection and ranging (LiDAR) technology is used to map distance to surrounding objects.
To properly train the multiple models and neural networks, a variety of annotations are required to identify and contextual things like road lines, traffic signals, road signs, objects in and near the road, depth and distance, pedestrians, and all the other relevant information on the road. While it’s important to have accurate segmentations down to the pixel level and tight bounding boxes, you also want annotators you trust to apply subjective judgements.
Dealing with subjective judgements
The question of what constitutes good and bad driving is not necessarily objective. How to deal with other drivers on the road is not as simple as just following traffic laws. Determining what to do if an object rolls into the path of your car is not a static decision. It takes drivers years of experience to become comfortable adapting to changes in the environment while driving and responding to other drivers. So, the question becomes how do we teach our models to make these types of critical decisions?
Google’s self-driving algorithm “calculates the probability by risk magnitude, compares it to the value of information to be gained, and uses that to make decisions.” Using a point system, it calculates the value of different scenarios and makes quick decisions on the best calculated course of action. Highly accurate annotations help train these algorithms to make the best decision consistently as they’re programmed.
Honda breaks down a process for annotating data to train self-driving models to make decisions. It includes an annotation on the goal, an annotation on a stimulus or external event, the cause of that event like congestion, and finally an attention point like the behavior of a pedestrian. This process is to model how a driver intakes and processes information when making a decision in order to accurately train the algorithm. Annotators help ensure these algorithms perform liked experienced drivers by labeling those behaviors and making judgements.
For example, if a person is standing on the curb facing the road they are likely planning to cross the street, even if it is not a crosswalk. However, if the person is in the same spot with their hand raised they are more likely hailing a cab. A skilled annotator would understand the difference in intent. Without that nuanced judgement to inform the model, the autonomous car would stop and wait for someone to cross who had no intention of crossing, causing an unnecessary traffic jam.
Subject Matter Expertise
Annotators don’t only annotate data; they also provide subject matter expertise. For example, it is important to work with annotators in different countries and regions, because each one has different traffic laws, which have to be taken into account during the labeling and training process. Different countries and even regions within a country have cultural differences in driving styles where drivers consistently speed and weave more aggressively while in other regions drivers proceed at a more leisurely pace. It is important for an autonomous vehicle to be able to match those styles. Beyond that, due to the complexity of the data, it is a good idea to staff your annotation project with professional annotators who will be accountable to quality. Professional annotators have a structured process to ensure accuracy and quality.
Pixel Perfect Accuracy
Beyond expertise, professional annotation companies like Innodata have advanced tools to achieve pixel perfect accuracy. When aiming to achieve 99% accuracy for something as important as autonomous driving, tight bounding boxes, pixel level segmentation, and precision across other annotations is extremely important. While the technology for simpler annotations is available for use for amateur annotators, the technology needed to perform annotation on LiDAR and radar data is limited and requires experience.
Innodata not only has the expertise and tools to achieve quality, we also have a proven methodology. This process includes using double pass annotation. In this method different annotators label the same set of data. Then where there are disagreements, an adjudicator makes the final decision on the correct annotation. Quality assurance assessments are done by an independent expert who reviews a representative random sample of the data set for accuracy and the determination of quality score is based on agreed upon metrics. If a dataset fails to meet the established quality benchmark, the dataset is reprocessed and reworked.
In addition, annotators are measured on individual quality to ensure their performance meets benchmarks. Using an inter-annotator agreement which measures how difficult or subjective a task is and how often annotators agree is one metric used. Annotators are also given a consistency score, which measures how consistent they are on the performing the same type of annotation. QA experts also conduct random spot checks to measure the ongoing quality of individual annotators quality. Annotators with the highest quality scores are assigned the most difficult datasets.
How Innodata Delivers
Innodata’s combination of expertise, technology, and dedication to quality make it the ideal partner for the complex annotations that autonomous vehicles require. By trusting us with your data, your data science teams can focus on innovation. We meet with your team to align on your needs, establish quality metrics, and develop an approach to achieve quality. We then select subject matter experts for the project with domain expertise and extensively train our annotators. Our annotation platform streamlines the work and helps us achieve faster time to value. Finally, the high-quality data we deliver strengthens the ML model and helps it achieve the desired performance.
Accelerate AI with Annotated Data
Check out our white paper on 4 Steps to Build Truly Intelligent Machine Learning Models