

What is Computer Vision?
The role of Image & Video Annotation In Computer Vision
“If we want machines to think, we need to teach them to see.” Fei-Fei Li
Computer Vision (CV) is a field of research and industry focused on enabling computers to see. By combining machine learning and computation, machines are able to build visual systems that allow them to identify, contextualize, and understand the visual world the way humans do.
One of the challenges of computer vision is that “seeing” is a complex process that we are still trying to understand. The more we understand how our vision works, the better we are able to replicate this in machines. Broadly speaking, our eyes are advanced sensors that take in light and feed this information to our visual cortex. Here a variety of neurons process the stimuli to detect color, shape, motion, and finally derive meaning. Computer vision works in a similar way. Cameras take in light to capture images that are then processed to derive meaning. Deep learning uses convolutional neural networks (CNNs), which references the neural networks that process information in our brains.
As you can see there are multiple components that go into “seeing,” which is why computer vision draws from a myriad of disciplines:
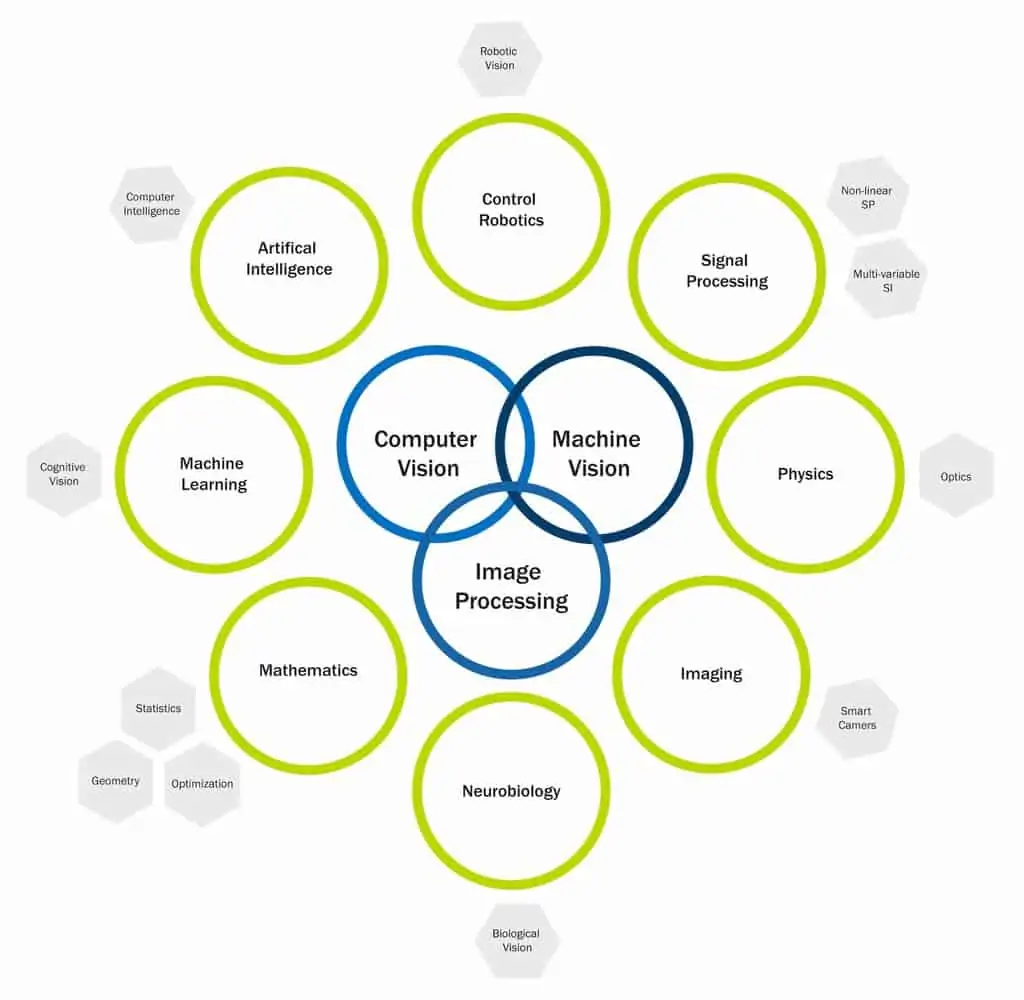
Researcher Fei-Fei Li, quoted above, was the first to use labeled data to generate mathematical models from images. Instead of hard coding what a cat looks like, the team showed labeled photos of cats of different breeds and various positions. This allowed the model built up its own idea of what a constitutes a cat, mimicking the way we learn to identify objects. This was a huge break through that helped spur the evolution of traditional software with rule-based systems, lines of code, and one model per problem into Horizontal AI with tunable base models that continuously evolve by learning from examples.
The Role of Image & Video Annotation in Computer Vision
With the ubiquity of cameras in mobile devices staggering amounts of visual data is produced every day. But only a small portion of this data is being leveraged because it lacks organizational structure. The two most prevalent AI techniques for computer vision, machine learning (ML) and deep learning both rely on high-quality training data to learn from, before it can ingest and make sense of raw data.
High-quality or “ground truth” training data has been mapped to a specific taxonomy, or classification system, that answers the domain specific questions one has about the data. This requires human-in-the-loop subject matter experts to accurately annotate the objects of interest as well as an AI-enabled annotation platform to support the labeling tools and automate the most tedious parts of the task.
Garbage in, garbage out
Good data is one of the fundamental building blocks of computer vision. In traditional software, poor data input guarantees inaccurate output. But with ML and deep learning, feeding a model inaccurate data not only ensures useless output but also damages the development of the model. Bad data forms bad habits, which are hard to break. Training is part and parcel to model development and by extension its functionality.
Computer Vision in Action: How Industry is Capitalizing on this emerging technology
Computer Vision is finding its way into a wide variety of industries and consumer products that allow machines to make quick, accurate predictions and decisions. Here are just a few examples of CV’s useful applications:
Photo search: “Search,” knowledge and data systems that rank, sort, and present information based on relevance to a query, has been somewhat limited by what someone is able to describe using text. People are often looking for something that is difficult if not impossible to describe, a problem which has plagued the Ecommerce industry. Now search engines are applying CV to recognize and match objects in new photos taken at a different angle in different light. Another way CV is enhancing search.
Real-estate companies, for example, are leveraging CV to enrich the metadata of their listings to optimize their search rankings and drive lead generation.
Frictionless shopping: Retailers are reimagining the shopping experience with computer vision. They are building stores in which you can walk in, pick out what you want, and walk out without ever going through check out.
Autonomous vehicles (AV): Level 2 autonomous vehicles are already on the road using CV to offer driver supervised steering, acceleration, braking, and even parallel parking assistance. Small fully autonomous vehicles are navigating sidewalks to deliver packages. AV will become more and more common place as the global market is expected to expand at a CAGR of 63.1% over the next ten years.
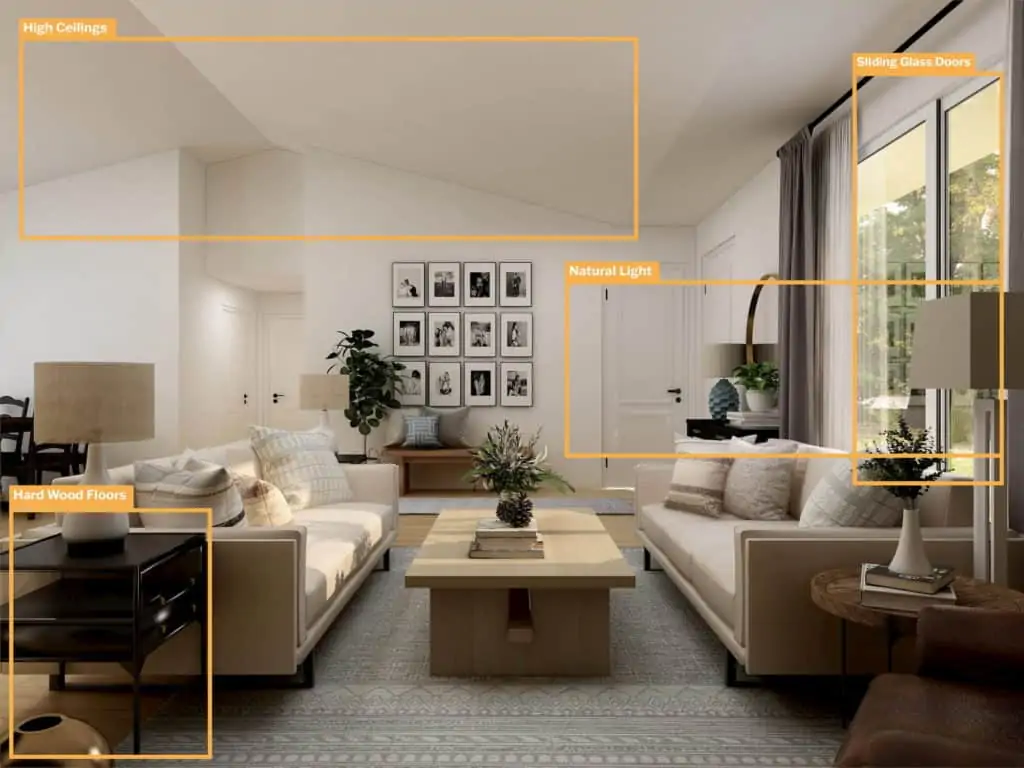
Home Décor: DIY decorators can now “try before they buy” by uploading a photo of the room they want to redo. The CV model creates a detailed virtual room with the scaled dimensions and accurate lighting. They can then change the wall color, light fixtures, add shelving, strip molding, etc. instantly exhibiting their vision for the space, before they buy a single can of paint.
Robot vacuums: Using CV to map out spaces and avoid objects like chair legs and toys, the global vacuum cleaner market was valued at 8.19 billion USD in 2019 with a CAGR of 24.4% for the next seven years.
Accelerate AI with Annotated Data
Check out our whitepaper on 9 best practices from industry leading data-driven companies