

Fine-Tuning, Prompting, and RAG – Which Customization Method is Best for Your AI Model?
Large language models (LLMs) have ushered in a new era of AI-powered language applications. To maximize their potential, they need to be adapted to your specific use case. Different methods come with varying levels of complexity, cost, and effectiveness for your business needs. In this article we’ll examine each approach, explaining how it works and its ideal applications. Here’s a deeper look at three primary techniques:
Full Fine-Tuning: Deep Adaptation for Specialized Tasks
Fine-tuning takes a pre-trained LLM and further trains it on a specialized dataset closely aligned with your desired use case. The process gradually adjusts the model’s vast array of internal parameters, allowing it to deeply internalize the patterns, vocabulary, and nuances specific to your domain.
How Fine-Tuning Works:
- Initializing with Pre-Trained Weights: Instead of starting from scratch, fine-tuning takes advantage of pre-trained knowledge. It begins by selecting an existing, powerful large language model (LLM). This LLM has already been trained on massive datasets, giving it a wealth of knowledge. Fine-tuning leverages this pre-trained model’s parameters as a starting point, allowing for faster and more specialized training on your specific task.
- Customizing with Specialized Data: After the model has been initialized with the general-purpose datasets, it can then be customized with the specific kind of data you want it to perform better on. This dataset should represent the tasks or domain-specific knowledge you’re interested in. For example, if you’re fine-tuning a model to perform legal document analysis, your dataset should consist of many legal documents. This data can be authentic data that you provide, or synthetic data that we prepare for you.
Best For:
- Highly Defined Use Cases: Fine-tuning can achieve excellent results when you have a clear, specific task in mind, such as classifying customer support tickets or analyzing the emotional tone of social media posts about your industry.
- Long-term, High-Volume Engagement: Fine-tuning demands computational resources and time, making it best when you expect frequent, ongoing use of the model in the targeted domain.
Prompt Engineering: The Finesse of Well-Crafted Instructions
Prompt engineering doesn’t change the LLM’s internal parameters directly. Instead, it focuses on meticulously crafting the text input (the “prompt”) that you provide to the model. By understanding how LLMs interpret language, you can guide the model to produce the kind of output you need.
How Prompt Engineering Works:
- One-Shot and Few-Shot Learning: Prompt engineering often leverages the LLM’s ability to interpret instructions and examples without a single additional training example (one-shot), or with just a few examples (few-shot).
- Templates and Formatting: Prompts can range from simple questions to complex templates with placeholders for the model to fill. Effective prompts may include desired output formats, specific examples, and even constraints to prevent undesirable outputs.
Best For:
- Prototyping and Rapid Iteration: Trying out different tasks? Prompt engineering allows fast experimentation without the overhead of data collection and retraining.
- Highly Versatile Model Use: If you need the same LLM to perform various tasks depending on the situation, tailored prompts are the way to nimbly change its behavior.
Retrieval Augmented Generation (RAG): Informed Responses Based on Solid Facts
RAG combines the generative capabilities of LLMs with the precision of traditional knowledge retrieval systems. The LLM uses the query to access relevant documents from a pre-existing knowledge base. It then generates a response, integrating information from those documents for better factual accuracy and context.
How RAG Works:
- Two-Stage Process: RAG splits the process. First, a “retriever” component ranks and selects relevant documents from the knowledge base based on the input query. Secondly, a “generator” model processes the retrieved text along with the original query and then creates the final response.
- Knowledge Base Integration: The knowledge base can be structured (e.g., Wikipedia) or unstructured (e.g., your company’s internal documents). RAG systems need a robust way to index this knowledge for efficient retrieval.
Best For:
- Tasks Requiring Grounded Facts: If responses need to be verifiable against a specific information source, RAG provides a significant advantage.
- Mitigating LLM ‘Hallucinations’: LLMs are prone to generating plausible sounding but incorrect text. RAG helps combat this by anchoring responses in retrieved documents.
Choosing the Right Approach
Selecting the most effective LLM tuning method for your application depends on several factors. Here’s a deeper look:
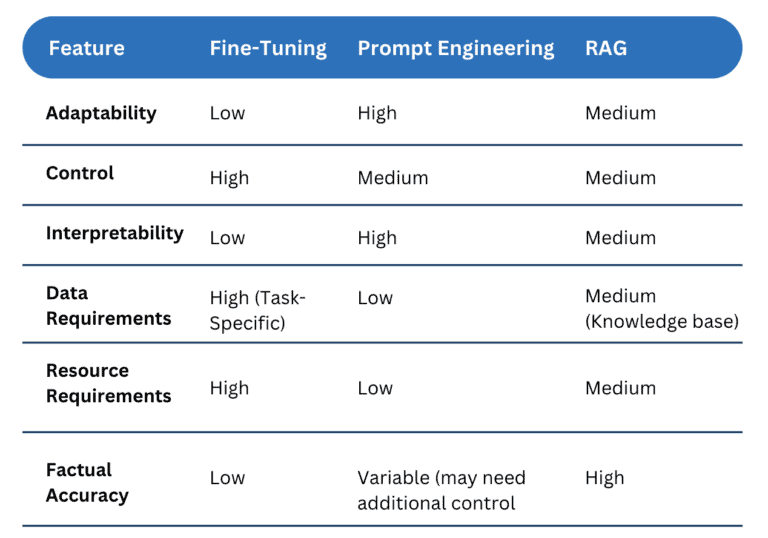
- Specificity of Your Task: Highly specialized tasks generally benefit most from fine-tuning’s deep adaptation. If your task involves standard language use with less domain-specific nuance, prompt engineering or RAG might be sufficient.
- Data Availability and Quality: Fine-tuning demands a sizable dataset of text relevant to your domain. If data is limited or noisy, prompt engineering or RAG could be more suitable. RAG also requires a well-structured, indexable knowledge base.
- Need for Factual Consistency: If your application requires strictly grounded responses verifiable against a knowledge source, RAG offers a clear advantage.
- Resource Constraints: Fine-tuning is computationally intensive and can take significant time. Prompt engineering is generally the lightest-weight approach, with RAG in the middle ground. Consider your hardware resources and time sensitivity.
- Control vs. Flexibility: Fine-tuning offers the deepest level of control over the LLM’s behavior but is less adaptable to new tasks. Prompt engineering grants high flexibility for rapid switching between tasks but can lead to less predictable results, especially on complex tasks. RAG provides a balance between the two.
- Interpretability: If you need to understand why an LLM makes certain decisions, prompt engineering and RAG tend to be more interpretable. Fine-tuning creates a more ‘black box’ model, although techniques exist to gain insights into what parameters change during the process.
- Evolving Tasks: If your use case is likely to shift significantly over time, prompt engineering or RAG offer easier adaptability compared to retraining a fine-tuned model.
- Potential Biases in Datasets: Be mindful of pre-existing biases in LLM training datasets, especially those used for fine-tuning. You’ll need strategies to mitigate the impact of these biases on your applications.
The Power of Combination
These methods aren’t mutually exclusive. You might achieve optimal results by combining them:
- Fine-tune an LLM on a task-specific dataset.
- Use prompt engineering to further refine its behavior for specific tasks.
- Leverage RAG to ensure responses are grounded in factual information from your knowledge base.
This combined approach can be particularly powerful for complex tasks requiring both domain expertise and factual grounding. For instance, imagine a customer service chatbot fine-tuned on a dataset of customer support interactions. You could then use prompt engineering to tailor its responses to different customer queries and integrate RAG to ensure its answers are factually accurate by drawing from a knowledge base of product manuals and FAQs.
By understanding the strengths and weaknesses of each approach, you can create a more robust and versatile LLM solution. Here’s a table summarizing the key considerations:
Innodata and Effective LLM Integration
At Innodata, we understand that effective LLM implementation requires careful consideration of your specific needs and goals. Our team of experts can help you navigate the various tuning methods and develop a customized strategy to unlock the full potential of LLMs for your organization. We can help you with:
- Needs assessment and gap analysis to identify areas where LLMs can bring value.
- Selection and implementation of the most appropriate LLM tuning methods.
- Data preparation and knowledge base development to fuel LLM training and retrieval.
- Evaluation and monitoring to ensure continuous improvement and alignment with your objectives.
Connect with us to explore how we can help you harness the power of LLMs.
Start a live chat with an expert.
Bring Intelligence to Your Enterprise Processes with Generative AI

Whether you have existing generative AI models or want to integrate them into your operations, we offer a comprehensive suite of services to unlock their full potential.
follow us